Picture a network—any enterprise network. What do you see? In almost every case, in almost every environment, you’ll find hubs and spokes of hubs and spokes all the way down. For network engineers, their focus may be even more narrow: innumerable clients, lots of switches, and fewer routers connected to a core. This classic on-prem topology has served reliably since the dawn of Unix time. But what you don’t typically see—even in hybrid environments—are multipath topologies blending star with mesh or other nonlinear routing options. Traffic flows in expressly defined patterns.
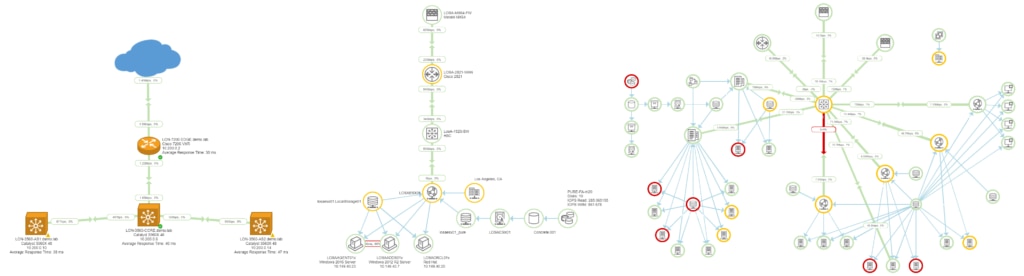
Sure, many organizations make exceptions for critical routes and provision at least some redundant gear and links. Failover is an efficacious sleep aid. However, as close-tickets-and-move-on-to-the-next-fire architects, we’re loathe to add any unnecessary routing complexity, and for good reason. More stuff means more to manage and more to break. We get away with it because fat-fingering config errors aside, network gear is much more reliable than storage and compute hardware. (Applications are in their own special category of weekend-spoiling surprise breakage.)
Nevertheless, times are changing again. Clear, bold lines of interconnection are transforming into multiple smaller paths of opportunistic routing and app protocol-specific dotted lines. The needs of increased access to data, betting our businesses on cloud and software as a service (SaaS) resources, hyperconverged infrastructure, and other new technologies are dragging in their internet-born, multipath ways.
The More the Merry-ish?
Before we get to specific strategies for reliable network operations in multipath environments, it’s important to acknowledge one thing. Wherever an organization is with adoption of multipath, it’s OK! No matter what vendors may recommend as essential, only the IT pros inside an organization can design and support the best infrastructure for their needs. Networking by its nature remains incredibly domain-specific, and there’s no sin in avoiding additional overhead to deploy and maintain multipath if there’s no clear advantage.
Cars, for example, don’t come from the dealer as a two-pack. We’re not eager to pay to double complexity and build four car garages to have “100% failover.” First, we long ago learned horizontal replication doesn’t provide 100% availability—only more nines—no matter how much redundancy is live. Second, some failures are acceptable—even rarely missing a meeting if the car won’t start. Our businesses are, and had better be, OK with
some failure. Great businesses aren’t measured on availability. Great businesses demonstrate the resiliency to accept unplanned shocks. Look no further than 2020, and you’ll notice a link between the organizations that rolled with unbelievable punches and those who had a tougher go of it.
Pragmatically, simpler topology is also easier to manage if Visio is the only available tool for the team to manually diagram the network. This isn’t to say multipath traffic can’t be visualized with manual tools, at least the broad strokes. However, increasingly complex networks aren’t being unloaded on the dock with boxes of additional headcount, and there’s only so much time in the day for detective work.
Multipath’s Primary Drivers
Have a coffee chat with most IT pros and two primary drivers for multipath networking emerge. Teams either desire to recast existing point-to-point network links into more versatile, aggregate bandwidth, and/or their business operations or environmental limitations necessitate self-healing infrastructure. Though these capabilities have been the basis of the internet from its inception, they’ve fortunately remained outsourced to Someone Else.
Someone Else is always the best place to put maintenance and monitoring chores distracting busy teams from delivering great user experiences. What’s changing is teams are no longer on the hook solely for tickets related to inherently multipath apps like Salesforce, Office 365/Google Docs, Teams, and Zoom. As multipath appears on-prem, IT pros become the Someone Elses who are responsible for also becoming multipath quality assurance experts.
Perhaps multipath’s most common enterprise application is in aggregating bandwidth in the form of Multipath TCP (MPTCP), RFC8684. Unlike Ethernet’s more basic 802.3ad link aggregation, MPTCP balances single TCP connections across multiple links to reach high throughputs without necessarily requiring more expensive bandwidth tiers. Which flavor of equal-cost multipath routing (ECMP) IT pros manage is usually determined by hardware vendor. Transparent interconnection of lots of links (TRILL) is favored by Cisco FabricPath and Brocade VCS, while Avaya, Alcatel, HP, and others are based on
802.1aq Shortest Path Bridging (SPB).
You might have seen a few articles on the success of multipath. For example, the 2014 Winter Olympics were the first "fabric-enabled" games using SPB and supported more than 50Tb/s of traffic across a patchwork of international link providers. Interop that year also implemented SPB for aggregation as well as supporting early SDN capabilities for their attendees.
*Sigh* Tech conferences… Remember chatting with the NOC engineers at shows like Interop and Cisco Live? Heck, does anyone remember getting on airplanes? I digress.
Unobtanium Chassis
If a networking team is fortunate, they overlook gleaming racks of new, seamlessly compatible, feature-encrusted network boxes from a single vendor. As wonderful as this sounds, for the other 99% of environments, this isn’t the case. We tend to run a collection of different vendors’ hardware installed in different business epochs under different business requirements. As with anything hybrid, the result is increased complexity, if only for expanded skills requirements to manage each technology the business adds.
Self-healing should be an obvious benefit of multipath networks. One might even expect it to be straightforward. Define a network service mesh capable of automatically rerouting around broken or congested links, problem solved, receive bacon. Just like with almost everything SDN, however, this is only true if you’re not the network team. Network services consumers’ worries stop at the network abstraction layer. That’s a Good Thing for productivity. Meanwhile, network admins must still configure, monitor, and troubleshoot multipath’s physical underpinnings, adding yet another source of virtual complexity atop layers 1 – 3.
Multipronged Monitoring for Multipath
Regardless of why and how IT pros become responsible for managing multipath networks, just as with SDN, hybrid, VPCs, or many other abstracted infrastructure models, multipath’s main challenge is limited visibility. How do teams troubleshoot (let alone proactively monitor) both multipath application traffic performance
and the physical links and hardware comprising them? Theoretically, if underlying link-level connectivity is maintained, at least a minimum acceptable subset of availability and bandwidth ought to be assured. In practice, however, this is rare.
First, because multipath networks are optimized, different types of traffic, application, and security requirements may result in wildly different routing paths. Each application may effectively experience its own unique network, even on a shared superset of available physical links. It’s another example of how applications increasingly determine network architecture rather than accepting a generic grid with old-school deterministic behavior. Even though application A’s users are singing the praises of the team, application B’s users may be flooding the ticket queue with issues even for the same set of routers, switches, and links.
The trick is to arm the network team with tools to monitor the network like an app, not by mimicking devices. For example, traceroute was once everything engineers needed (well, almost) to troubleshoot most network routes. Although it couldn’t determine why a node was introducing jitter, latency, or errors, it was handy for finding where to start. When hops were relatively immutable, ICMP Time Exceeded messages were good enough.
Today’s challenge is that unlike essentially every application, ICMP is based on UDP, not TCP. Ping packets get there or they don’t. Instead, most applications are based on TCP, with high expectations for delivery, consistency, and performance, even over networks like the multipath example below. And these application expectations don’t change even as routes shift minute to minute and application by application.
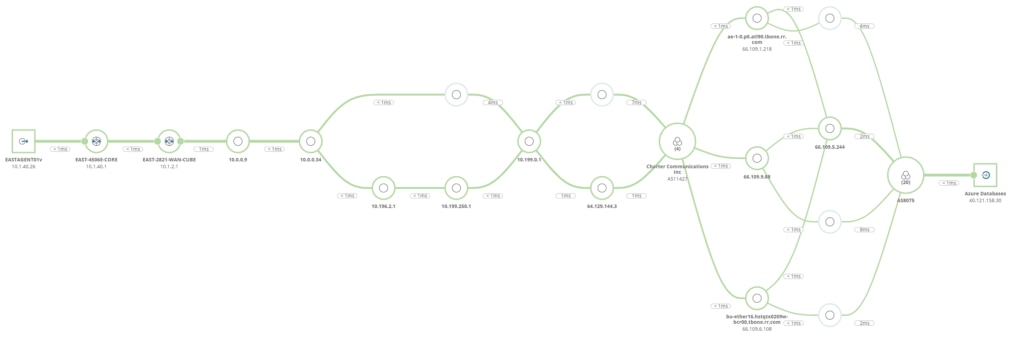
A majority of network requests from a given user to a given application may well follow the path of biggest pipes—least resistance—without issues. The user can also just as easily experience a sudden partial connectivity issue where a less used route is promoted, but with higher loss. Although the overall loss across all possible links may be low, identifying the 8% transit likelihood to an intermediate link with 50% packet loss is harder to spot. Ninety-two percent of users might have no issues, but the rest might be dead in the water. So, for the app’s users, is the network up? Without automatic and ongoing detection and monitoring of multipath topology, performance, and issues, this can be a difficult question for the team to answer.
Multipath Monitoring May Already Be in Your Toolbox
Look for tools capable of combining multipath monitoring with traditional
infrastructure monitoring. On good days, application-aware routing maps cast a reassuring green glow from NOC monitors. On less good days, quick access to the related details of physical devices and topology underlying multipath traffic may save hours of unexpected troubleshooting. No one enjoys working under temporal distress with a pacing VP. Start by revisiting the features of your current
network performance monitoring (NPM) platform. Vendors increasingly include these capabilities, and they’re only a how-to or an upgrade away.
Last, learn about multipath delivery from observing the internet. Not watching YouTube videos, but setting up example monitors for YouTube, Salesforce, Office 365, or other multipath endpoints. The internet isn’t just informing the design of enterprise networks—it’s a fantastic laboratory. Picking any application where IT pros are on the hook for tickets from infrastructure they don’t manage will work. Using the cloud and SaaS apps your business relies on as examples, you’ll quickly learn what types of issues cause the greatest impact to applications.
With so many staff members working remotely, most businesses today have no shortage of networks where users and applications seamlessly shift traffic routing without issue. Configuring an NPM solution’s multipath probe can help discover the secret life of applications and packets with no idea how they get from point A to point B. Once you’ve observed feral multipath application traffic on the internet, making sense of your enterprise network can be a piece of cake.

 Sure, many organizations make exceptions for critical routes and provision at least some redundant gear and links. Failover is an efficacious sleep aid. However, as close-tickets-and-move-on-to-the-next-fire architects, we’re loathe to add any unnecessary routing complexity, and for good reason. More stuff means more to manage and more to break. We get away with it because fat-fingering config errors aside, network gear is much more reliable than storage and compute hardware. (Applications are in their own special category of weekend-spoiling surprise breakage.)
Nevertheless, times are changing again. Clear, bold lines of interconnection are transforming into multiple smaller paths of opportunistic routing and app protocol-specific dotted lines. The needs of increased access to data, betting our businesses on cloud and software as a service (SaaS) resources, hyperconverged infrastructure, and other new technologies are dragging in their internet-born, multipath ways.
Sure, many organizations make exceptions for critical routes and provision at least some redundant gear and links. Failover is an efficacious sleep aid. However, as close-tickets-and-move-on-to-the-next-fire architects, we’re loathe to add any unnecessary routing complexity, and for good reason. More stuff means more to manage and more to break. We get away with it because fat-fingering config errors aside, network gear is much more reliable than storage and compute hardware. (Applications are in their own special category of weekend-spoiling surprise breakage.)
Nevertheless, times are changing again. Clear, bold lines of interconnection are transforming into multiple smaller paths of opportunistic routing and app protocol-specific dotted lines. The needs of increased access to data, betting our businesses on cloud and software as a service (SaaS) resources, hyperconverged infrastructure, and other new technologies are dragging in their internet-born, multipath ways.
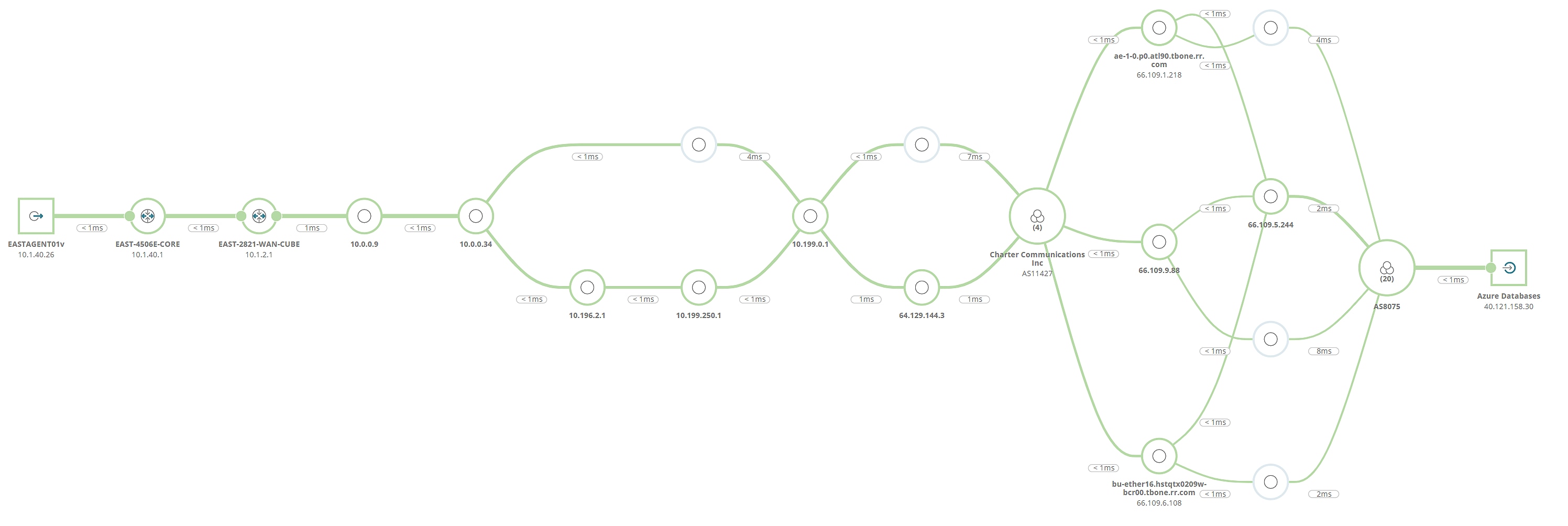 A majority of network requests from a given user to a given application may well follow the path of biggest pipes—least resistance—without issues. The user can also just as easily experience a sudden partial connectivity issue where a less used route is promoted, but with higher loss. Although the overall loss across all possible links may be low, identifying the 8% transit likelihood to an intermediate link with 50% packet loss is harder to spot. Ninety-two percent of users might have no issues, but the rest might be dead in the water. So, for the app’s users, is the network up? Without automatic and ongoing detection and monitoring of multipath topology, performance, and issues, this can be a difficult question for the team to answer.
A majority of network requests from a given user to a given application may well follow the path of biggest pipes—least resistance—without issues. The user can also just as easily experience a sudden partial connectivity issue where a less used route is promoted, but with higher loss. Although the overall loss across all possible links may be low, identifying the 8% transit likelihood to an intermediate link with 50% packet loss is harder to spot. Ninety-two percent of users might have no issues, but the rest might be dead in the water. So, for the app’s users, is the network up? Without automatic and ongoing detection and monitoring of multipath topology, performance, and issues, this can be a difficult question for the team to answer.





