One of the most common questions database professionals are asked by their systems and virtual machine (VM) administrators is “Why does the database server need so much memory?” You’ll get a more detailed answer to that question later in this post, but it’s important to understand a database engine is almost like a server within a server.
The database engine has its own memory management, and some even have their own internal operating systems to manage all work the engine is doing to retrieve and process data. This post provides an overview of how database engines operate and how it impacts your server metrics.
All That Memory
As noted, databases consume a lot of memory, this is by design. If you add more memory to a VM with a database engine, the database engine will probably consume all of the additional memory. The fact is, reading and writing directly to disk is slow compared to memory access, so the people who code database engines take advantage of memory as much as possible, as shown in
Figure 1.
 Figure 1 Representation of a database engine memory and disk layout
Figure 1 Representation of a database engine memory and disk layout
The background represents the memory subsystem typical of most database engines. Not all database engines include the two caches shown in light blue, but almost all have a buffer cache and use memory to sort query results, shown as the two larger boxes on the right.
The buffer pool caches frequently/recently used data blocks, so the engine doesn’t have to go to disk to retrieve those pages. On most database platforms, there are automatic processes to keep track of how long data blocks remain in memory without being used. If those pages turn “stale,” the database will automatically evict the long-unused pages to make room for new queries and process. Query and sort memory is allocated when a query plan gets generated, and is used when joining tables to provide query results. Additional memory may be required to support locking on database applications needing to support concurrent users.
If data blocks aren’t in the buffer pool after the query is executed, the engine will retrieve the data from the database files on disk. If there’s not enough memory to perform a join or sort operation, the engine will use the temporary database (or, in some open source databases, a file on the file system) to complete the sort. You can think of this process as being like the database engine paging to disk.
Just as with an operating system, database paging isn’t good for overall performance. The way to avoid it is by both tuning your queries to consume the fewest resources necessary and adding more memory. To understand if your database is using memory effectively, you need to look deeper than simple OS metrics, and analyze database-specific memory metrics inside the database engine. Examples include Page Life Expectancy in SQL Server, or SGAM percentage in Oracle.
Why Is CPU Use High?
CPU utilization is a little more simplistic to analyze than memory utilization. In general, high CPU use on a database server is indicative of a workload that’s not optimized. This can be caused by several conditions, including bad statistics on table columns and indexes, poor index design, scheduled jobs, and bad query patterns.
It might be that you have too much workload, even for an optimized database. Even having idle connections can consume memory and CPU resources, which can impact your overall concurrency. Still, while this can happen, the far more common issue is poor queries.
To resolve this, you need to look inside your database engine again to identify which queries are using the most CPU, and analyze how they can be optimized. One tip here is don’t just look for the queries with high CPU consumption; look as well for queries running frequently and consuming fair amounts of CPU. Often, these smaller queries can be more easily optimized and greatly reduce your overall CPU consumption. This situation is often called “death by a thousand cuts.”
How Much Storage?
Databases use a lot of storage—they persist data for a certain period of time (in many cases forever), which itself requires a lot of storage. That storage also needs to be fast, because, as mentioned, if the database can’t resolve the query from the buffer pool, it’s going to have to go out to disk to grab the data.
Beyond files, databases also have two secondary storage needs—for active transaction or redo logs, and backup files. Transaction logs are where relational database writes its changes first, before they’re persisted to the database file. As this process is a direct part of the transaction, it’s important to keep your transaction logs on fast storage.
Keep in mind transaction logs (or archived redo logs) can grow large during operations like the creation of an index, or large insert/update transactions. Backups, on the other hand, are generally fine using slower, cheaper storage as they aren’t part of the primary functionality of a database. It’s important to ensure your backups are on a separate storage device from your primary files, so when major device failure occurs, your data is still protected.
Let SolarWinds Do the Heavy Lifting
The SolarWinds
database management portfolio, Database Insights for SQL Server, Database Performance Monitor (DPM), Database Performance Analyzer (DPA), and SQL Sentry, offers an easy and cost-effective way to watch and alert you to problems within any of these areas.
Resource metrics provide information about how resources (such as CPU, disk, and memory) are being used at specific points in time. These metrics show what was happening in the rest of your environment during database slowdowns, and can provide context to help you identify the root cause of performance problems. When viewing resource metrics on the Resources tab in DPA, you can display baselines to compare values from a specific period to historical norms.
As you can see, these tools from SolarWinds can take your database performance to the next level. If you’re ready to save time and effort tracking down these problems,
request a demo with their database management experts.

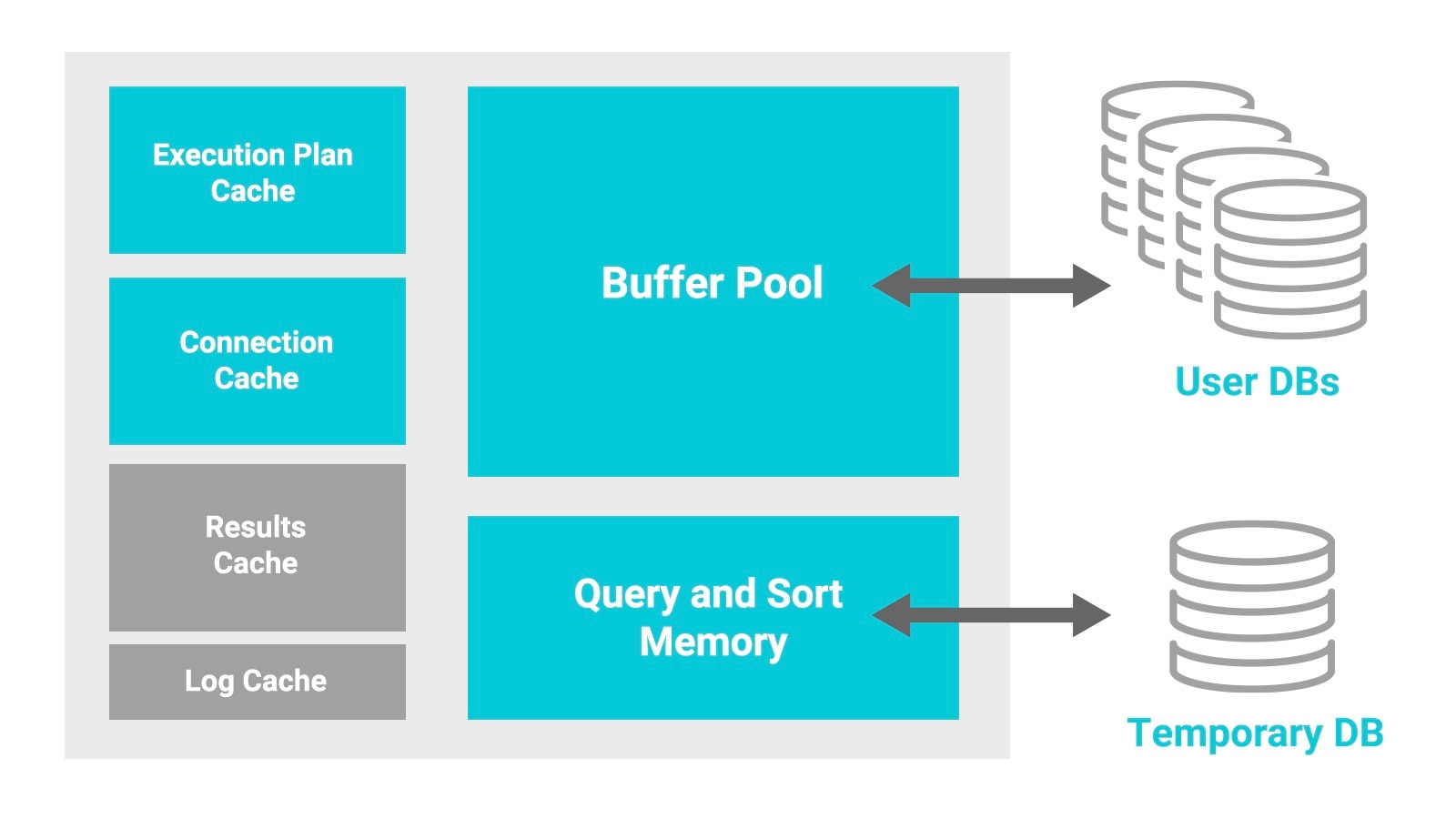 Figure 1 Representation of a database engine memory and disk layout
Figure 1 Representation of a database engine memory and disk layout


