Have you ever dealt with an application workload suddenly increasing and the demand on SQL Server begins to increase exponentially as a result? Maybe you’ve never had one of those “my solution to X problem just went viral, and everybody’s signing up” moments, but inevitably, at some point in your career, you’ll have to deal with a scalability limitation affecting performance and the business will look to you for a solution. Generally speaking, there are two types of scaling for SQL Server workloads; horizontally partitioning the workload across multiple servers or vertically scaling the workload with a bigger, single server.
SolarWinds database solutions are built to provide you with deeper insights into database health and can help you pinpoint performance issues typically within a few minutes. Find the solution best fit for your environment here.
Vertical Scaling—Bigger Hardware
In a world where hardware sizes and resources have doubled every three to four years, it might seem like “buy a bigger server” is a good solution but is it really? From an application and implementation standpoint scaling up is a fairly easy solution. You merely have to buy bigger hardware than the existing server and, after provisioning it, move the databases to the new server. It doesn’t typically require much investment in the application design or changes to anything other than connection strings. However, as the saying goes, there’s no such thing as a free lunch.
As a SQL Server consultant for the last 12 years, I’ve worked with numerous systems where an attempt at vertically scaling SQL Server resulted in slower performance and magnified problems for the workload. Sometimes bigger hardware (more CPUs and more memory) means bigger problems or, better stated, amplification of existing design bottlenecks impacting performance. In some cases, the scalability problems have nothing to do with the hardware resources though it may seem like they do. I like to use a lawn mowing analogy when I talk about scaling SQL Server because most people can relate to the example.
If I have an acre of grass needing to be mowed, there are multiple mowers out there having pros and cons associated with them. Consider the following table of different mower types, sizes, and costs with the amount of work expected from a typical adult using the machine.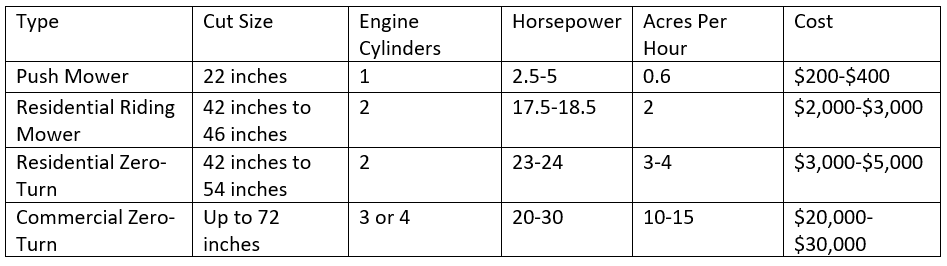
A standard push mower is relatively cheap, and a typical person can mow an acre in under two hours. A standard 42-inch riding mower should be able to cut the same acre in under half an hour, and a zero-turn mower should be able to do it in 15-20 minutes. However, despite owning one of the top end residential zero-turn mowers, it takes my son an hour to cut an acre of grass. Why?
Well, a typical adult on a zero-turn mower will mow in straight lines back and forth and produce a nice pattern of lines in the grass as they go, which also allows the fastest ground speed to be achieved along the majority of the cut. My son drives the mower like it’s a bumper car and spins circles and zig-zags all over the place; he calls it making it fun for him. He did the same thing on the standard riding mower we also owned before buying the zero-turn mower, and it still took him about an hour to mow an acre of grass. For the record, I can mow all five acres of my land in about an hour and a half in nice clean passes that keep my OCD in check, so I know it’s not the hardware. It took me around four hours to do all five acres with the traditional riding mower. The problem isn’t always the hardware being used; it could be a built-in inefficiency where the hardware being bigger/faster might bring it into the light.
While vertical scaling is relatively simple in terms of technical requirements, hardware cost is also significantly increased as it gets larger. It doesn’t always correlate to the same gains in performance ratio-wise. Going from a two-socket server to a four-socket server isn’t only a doubling of the cost for only the hardware. In general, as you double the number of sockets, the cost of the hardware can be as much as four to five times the price, depending on what decisions are made for processor and memory. Performance also doesn’t scale linearly with the size of hardware, and the more cores on a processor usually reduce the base clock speed of the processor and doubling the socket count usually also takes a performance reduction due to the overhead required to maintain coherency across sockets.
Horizontal Scaling – Dividing up the Work
The alternative to vertical scaling with bigger hardware is horizontal scaling by partitioning the workload or dividing up the workload across multiple smaller servers, often referred to as sharding. This typically requires a certain level of application re-architecture and can require significant time investments by the business to accomplish initially. However, once re-architected, the solution can be scaled easily by adding new shards to the configuration. Unlike vertical scaling, where the costs can start to become exponentially more expensive, with horizontal scaling, the costs are consistent as new nodes with the same processing power are added into the configuration, and maybe work is divided up with a load balancer.
Going back to the mower analogy—a commercial zero-turn can cut anywhere from 10-15 acres per hour under the right conditions. If we use the middle of the road for cut speed at 12.5 acres an hour and pricing of $25,000, how many push mowers would it take to accomplish the same thing? It would take 21 push mowers to do the same task in the same time, and the cost for the mowers would be a bit over $6,000. Seems wise, except now we have maintenance on 21 mowers, wages to pay for 21 workers, we need someplace to store them, and these are all recurring costs after the hardware purchase. Buying three or four residential zero-turn mowers probably wouldn’t make much sense when considering the total cost of ownership. We could rent the mower and save ourselves the maintenance costs and employee wages (basically a cloud solution, including auto-scaling maybe), but we’d have to pay the rental fee each time we use the mower, but we can scale the size up or down based on the amount of work we have to do easily as long as the vendor provides a mower of the size we need.
So, where would you leverage horizontal scaling? Well, many companies already have done some level of horizontal scaling using availability groups and readable secondaries to offload their reporting and other read-only queries to another server, albeit at the higher licensing costs of SQL Server Enterprise Edition. You can do the same thing with transactional replication to multiple subscribers, with the added benefit of using the Standard Edition for the subscribers to keep licensing costs lower. Additionally, you can customize the indexes on the subscribers for the workload and only publish the required tables for what the application needs instead of keeping the entire database replicated and creating all indexes on the primary replica of an availability group. Horizontal scaling also provides better fault tolerance and redundancy compared to one big machine, which could be a single point of failure.
Scaling horizontally for reads has been relatively easy with SQL Server, but what about writes? This is where things can become a bit more challenging to implement. To be perfectly honest, for today’s write workloads, the schema design usually becomes a bottleneck well before the hardware does. While there are a few different methods of sharding/partitioning write workloads, they’ll all generally require changes to the database schema design to either create separate logical partitions of the data as different databases or to use one of the replication architectures allowing there to be more than one writeable copy of the data. For example, merge replication requires a rowguid uniqueidentifier column to be able to uniquely identify rows. Peer-to-peer replication requires not using identity columns or manual identity range management for each of the peer nodes in the topology.
In my experience, it’s generally easier to implement a sharding solution based on a logical division of data into separate databases, for example, by country, state, client, etc. This is similar to having my son mow the front pasture of my property while I mow the back pasture on a different mower. The work is divided, though not evenly, as most of my land is the back pasture, which can be done on the faster mower by me since it would take him an hour to do the front no matter what. I’ve worked with lots of multi-tenant database designs where everything is crammed into a single database, multiple terabytes in size. These are ultimately huge collections of technical debt, eventually reaching the point where going bigger is not possible, and the only solution is a redesign of the entire architecture to scale.
Determining the Best Scaling Strategy
There’s no single answer to which strategy will be best; as my colleague Paul Randal likes to say, “It Depends!” You might never have to deal with scalability issues in your current job, and SQL Server is handling a CRM database with modest reporting needs that a single machine or VM can take. And, it may be you’re still at a point where scaling up still makes sense. However, the best time to begin the implementation of a horizontal partitioning strategy is while the data is as small as possible. The larger the data set becomes, the more challenges with sharding the data you’ll have, as creating the initial sharding deployment may require prolonged downtime the business won’t accept. If you can run your workload in the two-socket space with adequate performance and still have room for growth, and you have a multi-tenant design leveraging a single database, I would start having the discussions today about scalability and the future, especially before upgrading the existing machine to a four-socket server.
By the time you’re in the four-socket space for hardware, you’re one step away from being out of options in terms of vertical scalability. You’re also starting to flirt with the limits of SQL Server workload testing, and the larger the system becomes, it’s possible to run into limitations around spinlock contention, memory management, or a specific feature being used. While Microsoft will certainly be interested in investigating anything related to SQL Server as a product imposing a limit on performance, keep in mind it could take Microsoft a long time to come up with a solution addressing a bottleneck in the SQL Server design. Basically, you’ll be waiting for Microsoft to do what you wouldn’t do previously to scale your own application.
Scale Up vs. Scale Out
When it comes to what’s the best strategy for scaling SQL Server to handle an increasing workload, there are multiple considerations, including:
- Where are you or your business heading, and what does it mean for the data requirements?
- Re-architecting the application to scale horizontally at the data tier the same way the web tier or application tier scales or are you still stuck in the single large “mainframe” mentality as a business?
- Could you scale your workload to 10 or a hundred times the requests per second you handle today? And,
- What if you actually needed to? Also,
- How long would it take, or could your job be at risk for replacement by someone who can architect the types of solutions able to scale at this level?
These are sometimes uncomfortable questions, especially if the answer is you don’t know how to architect and optimize a cost-effective solution scaling in this manner; you aren’t an application developer or architect. However, do you know if they’re even thinking about those types of challenges, and have you had the talk with them to find out how they’d handle a situation where the data tier had to scale at the same rate as the application tier? As I mentioned above, the earlier you can start planning for horizontal scaling, the better.



