LOGICAL_CLOCK.
The solution developed—which achieves faster replication via group commit and a carefully calibrated delay—can offer huge replication improvements, but its implementation isn't immediately obvious or intuitive. This blog provides a fuller description of how the team arrived at the solution Preetam outlined.
Bad Replication
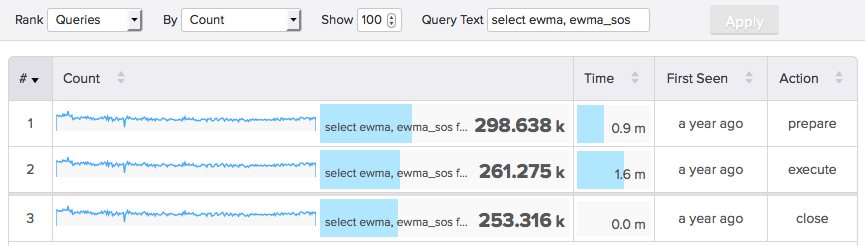
Things started when Preetam noted replication delay had been getting worse for some shards, in fairly periodic waves. These were the kinds of results we were seeing: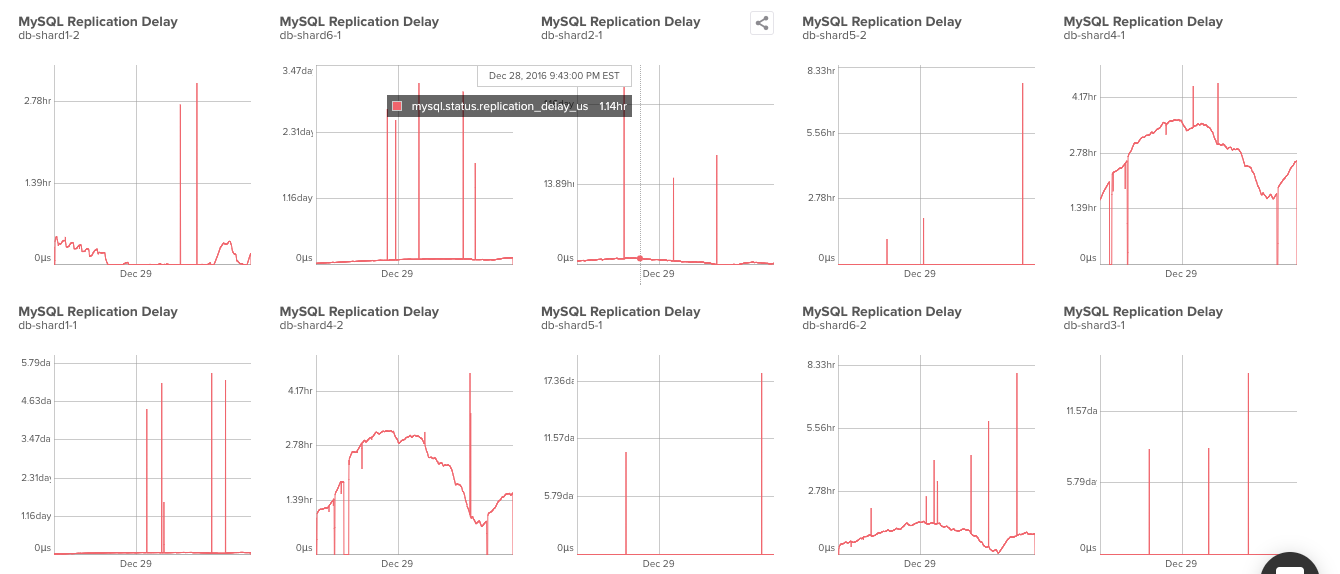 As Preetam wrote in his post, a solution to these periodic delays was elusive. "It wasn't about resources. The replicas have plenty of CPU and I/O available. We’re also using multithreaded replication (aka MTR) but most of the replication threads were idle."
There were a couple of attempted fixes attempted right away:
As Preetam wrote in his post, a solution to these periodic delays was elusive. "It wasn't about resources. The replicas have plenty of CPU and I/O available. We’re also using multithreaded replication (aka MTR) but most of the replication threads were idle."
There were a couple of attempted fixes attempted right away:
- To speed up queries overall, double the instance and buffer pool sizes. It didn't help.
- Increasing slave-parallel-workers didn't make a difference, and most seemed idle anyway.
First Look at LOGICAL_CLOCK
Interestingly, even at this early stage, the team was aware of MySQL 5.7's LOGICAL_CLOCK parallelization policy. But initial experiments with it offered nothing of value, even though the MySQL High Availability team had written that it offers optimal concurrency. The MySQL 5.7 reference manual defines LOGICAL_CLOCK like this:
LOGICAL_CLOCK: Transactions that are part of the same binary log group commit on a master are applied in parallel on a slave. There are no cross-database constraints, and data does not need to be partitioned into multiple databases.
--slave-parallel-type=LOGICAL_CLOCK resulted in slower replication than --slave-parallel-type=DATABASE. It didn't appear to offer an answer. [Spoiler alert: we had yet to develop a key component of how to optimize the new policy, involving grouping more transactions per binary log commit.]
Serious Delays
We weren't sure the best way to proceed. One major cause of bad replication can be long-running queries, because they parallelize on the master but serialize on replicas. A workaround can be to break big queries into many small ones. Or, to really fix the problem, get rid of MySQL replication altogether! Those weren't immediately viable or practical solutions, though. At this point, a few of our shards were suffering some serious delays. The worst was behind by at least 16 hours. Here's a 30 day snapshot: We looked back at the master to understand the replica more fully. Looking at the write load on the master can be a good way to analyze what the replica's write load is doing, which might be making lag.
We examined the Top Queries related to the lagging shards and noted that there had been a great deal of metrics, sketching, and—probably most importantly—downsampling surfaced over the past month.
We looked back at the master to understand the replica more fully. Looking at the write load on the master can be a good way to analyze what the replica's write load is doing, which might be making lag.
We examined the Top Queries related to the lagging shards and noted that there had been a great deal of metrics, sketching, and—probably most importantly—downsampling surfaced over the past month.
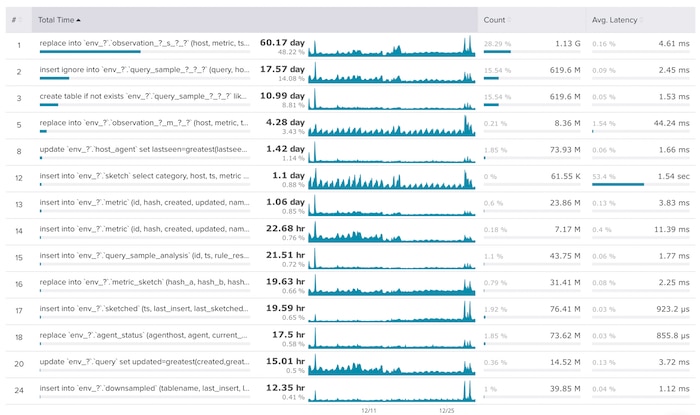 The downsampling in particular had increased dramatically, though it still wasn't the top contributor to these top queries. However, that kind of change is significant; delays like the ones we were seeing can be the result of redownsampling, causing duplicate work.
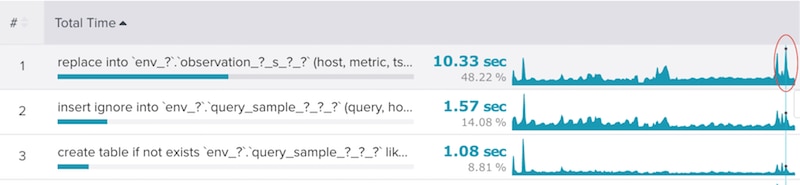
In the screenshot below, note where the cursor is hovering over the sparkline. We looked at the total of execution time in the pictured period—which, in this case, was ten seconds. Hovering over a point shows an instantaneous value as a rate; here, that essentially means ten seconds of execution per second. So, the concurrency of query #1 is 10x. If this isn't possible to parallelize at least 10x on the replica, the replica won't keep up with the master.
The downsampling in particular had increased dramatically, though it still wasn't the top contributor to these top queries. However, that kind of change is significant; delays like the ones we were seeing can be the result of redownsampling, causing duplicate work.
In the screenshot below, note where the cursor is hovering over the sparkline. We looked at the total of execution time in the pictured period—which, in this case, was ten seconds. Hovering over a point shows an instantaneous value as a rate; here, that essentially means ten seconds of execution per second. So, the concurrency of query #1 is 10x. If this isn't possible to parallelize at least 10x on the replica, the replica won't keep up with the master.
The Return of LOGICAL_CLOCK
At this point, Preetam returned to the original idea of experimenting with LOGICAL_CLOCK. But this time, he also took note of binlog_group_commit_sync_delay, introduced in MySQL 5.7.2+.
Controls how many microseconds the binary log commit waits before synchronizing the binary log file to disk… Setting binlog-group-commit-sync-delay to a microsecond delay enables more transactions to be synchronized together to disk at once, reducing the overall time to commit a group of transactions because the larger groups require fewer time units per group (MySQL Reference Manual).
We applied a commit delay to our straggling shards… and voila. Before: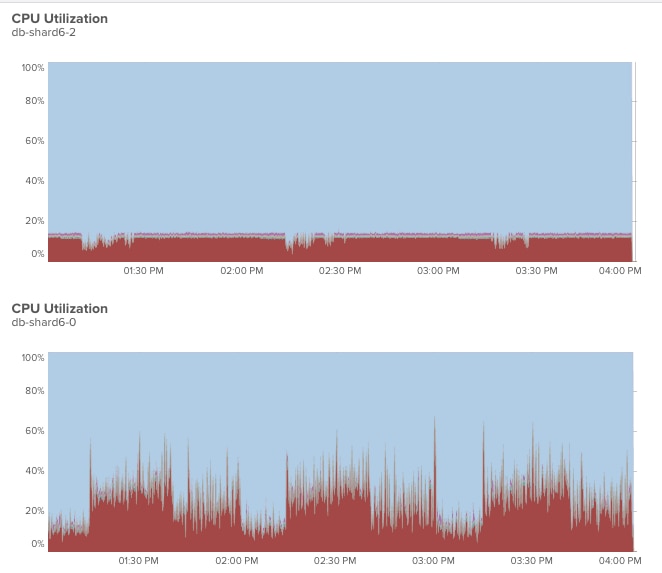 After:
After:

 It took a couple tries to find the exact setting for the
It took a couple tries to find the exact setting for the binlog_group_commit_sync_delay. We started with 50 ms, but that was too much. Overall query latency went up (by ~50 ms) and caused the consumers to fall behind.
On the other hand, 500 µs was too low, and it caused the replicas to fall behind again.
At first, 3 ms appeared to be the sweet spot, and resulted in what looked like overall replication improvement. Success! However, over the next few days, the replicas eventually started falling behind again, and we responded by upping the delay; it's at 10 ms now.
This last delay increase actually confirmed some feedback Jean-François Gagné commented on Preetam's blog post shortly after it was published. Jean-François wrote
In my experience, 3 ms for delaying commit on the master is not a lot. On some of my systems, I am delaying commit by up to 300 ms (0.3 second), but this system does not have a very high commit rate (transactions are "big"). If 3 ms is working well for you, my guess is that you have a very high commit rate and very short transactions.
He also kindly shared these links for additional reading:[1]: http://www.slideshare.net/Jean...
[2]: https://blog.booking.com/evalu...
Overall, this was an interesting issue to address and not at all as obvious as one might think. We hope the solution we arrived at is useful for you and your organizations, especially if these MySQL settings were previously unfamiliar.