
Periodically, we hear proclamations that SQL is “dead.” For a long time, people have been commenting on how NoSQL stores are the inevitable grim reaper as far as RDBMS systems are concerned. I think we all remember the “web scale” memes…
This meme is more than 10 years old, and MongoDB is doing great. Does that mean we’ve all ditched traditional databases? Absolutely not. In fact, the use of SQL-based systems is growing. So, let’s look at how that’s possible.
Data Growth
Let’s start with a visual of how much data has been—and is anticipated to be—created each year.
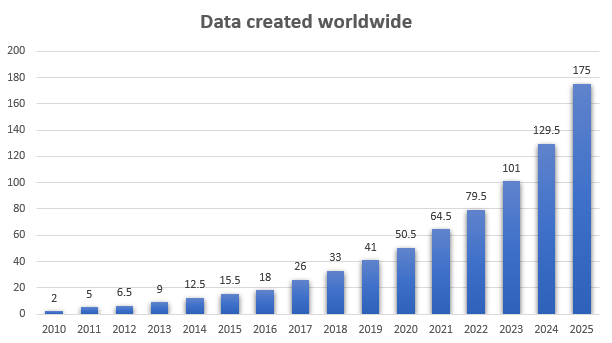
Source: Statista
The units in this graph are zettabytes. To save you from having to Google what a zettabyte is, here’s how that’s defined:
1 zettabyte = 1000 exabytes = 1 million petabytes = 1 billion terabytes = 1 trillion gigabytes
Around 175 trillion gigabytes of data is anticipated to be generated in 2025 alone. That is some explosive growth!
Obviously, these are only estimates. And, a lot of this data isn’t stored in any form of database. For example, videos aren’t typically good candidates for database storage. Sure, we might use a database to store a catalog of videos, but the primary data would be kept in a different form of storage.
Tying Data Growth to Usage
What we can infer from this growth is that structured/semi-structured data storage is growing as well in the following two ways:
- The amount of data that we’re storing each day is getting bigger
- The sum of data that we’re storing is getting exponentially bigger and the periods for which we have to retain data rarely change
It is difficult to tie data growth into revenue from the likes of Microsoft or Oracle specifically for RDBMS systems, but the data from Microsoft’s 2019 annual report stated their Intelligent Cloud division saw revenues of $27.4 billion, $32.2 billion, and $40.0 billion for 2017, 2018, and 2019, respectively. SQL Server is a part of Microsoft’s Intelligent Cloud division, whether that’s in Azure or on-premises installations, and it’s a pretty safe bet that the usage of SQL Server is increasing, even if we can’t be sure by how much.
We can look at various sources for information about the usage of particular databases, but it can be difficult to get a holistic, independent view. A survey of the SQL Server community will show everyone is using SQL Server, and an open-source focused survey will show everyone is using MySQL or Postgres. However, a graph of database usage by type (summarized from the June 2020 DB-Engines Ranking report) can give us an indication of the breakdown between RDBMS and open-source databases.

Source: June 2020 DB-Engines Ranking Report
This graph effectively shows that relational database usage still accounts for roughly 75% of the market. Another interesting source of information is Stack Overflow Insights, which provides information about trends.
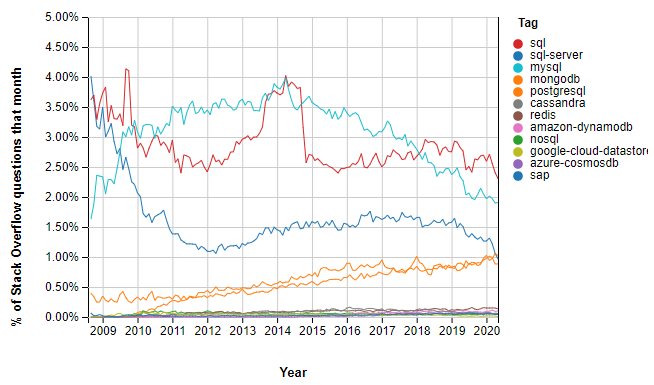
Source: Stack Overflow Insights
This is an interesting chart. At first glance, you might say “Oh, well the questions about traditional RDBMS are lowering in volume, so they are getting less popular.” However, that doesn’t reflect the fact that often, Stack Overflow already has the answer to a question you might ask. Really this chart is saying “How much is the question base growing for this topic?” What this chart shows is that there is still growth for both RDBMS and NoSQL systems.
I thought NoSQL Was Taking Over the World?
NoSQL stores have varying specialties, including:
- Key-Value storage
- Document storage
- Graph storage
- Time series storage
- Column-oriented storage
However, one thing that NoSQL stores do not do very well is ACID compliance. For example, you can update several rows in a transactional fashion in Azure Table Storage or CosmosDb in table mode if the following constraints are met:
- All changed entities must share the same partition key
- At most, 100 entity changes can be present in the batch
This turns our thinking about transactional processing on its head somewhat. The first point effectively ensures that we need to change our data model design so that entities we want to update within a transaction share the same partition key. This sounds simple until you consider that the partition key is effectively the equivalent of the first column in an index in RDBMS stores—you really need to be searching by that. For a sales order with items, you could craft row keys such that you have SUMMARY for the order summary data (i.e., customer identifier, store identifier) and you have ITEMx for the item data. Job done, right?
Not quite.
This works well for the very limited example of a sales order with items if we are happy to accept a limit of 99 items in a sales order. Once we start thinking about the other types of data that we would like to store for a transaction (e.g., payment methods, issued coupons/incentives, timing data), suddenly that 100 entity limit becomes quite limiting. If we want to modify other data as well (we might want to update a stock record when an item is sold, for example), then it becomes impossible to design a partition key scheme in which all of these updates fall within a single partition.
Isn’t That a Bit of a Gotcha?
In some ways, yes. However, we looked at a single example in which ACID compliance was very important. We want to be sure that a record of the sales order is completely recorded at the point of failure. There are many different scenarios for data in which we don’t require such a stringent guarantee. Does it really matter if we miss a couple of views when modifying the view counter for a video and the system fails? Or, when it comes to profile likes or comments, does it matter if we don’t record one when an outage occurs?
The answer to those sorts of questions is dependent on the system and the type of data being stored. It can also be affected by the architecture of the system. If we have a service that implements CQRS, then it is very important that everything be recorded in the command store. However, the query store can be completely rebuilt at any time from the command store, so we don’t need such strong guarantees around system failure. Similarly, with event sourcing, our event store is critical but the data stores that belong to individual services can be rebuilt by replaying those events.
One of the key benefits of microservice architecture is that each service can use the most appropriate technology to service its requirements. This is true at the data model layer, too. Some data models will have strong transactability and failure requirements, others are more tolerant of failure and need to support massive scale out.
In the HighScalability.com 2019 Database Trends report, there is a graph that nicely reflects this mix. The survey question asked, “If you use multiple databases in your system, which types of database do you use?” The answers were “NoSQL only,” “SQL only,” and “Mixed.” The responses to that survey further cement the idea that a mixture of data storage technologies is appropriate in most systems.
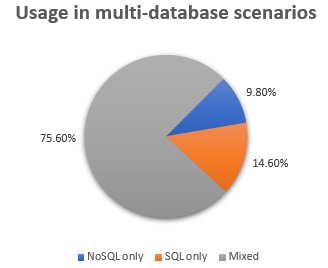
Source: HighScalability.com 2019 Database Trends Report
So, SQL Isn’t Dying After All?
No, SQL isn’t dying. There are many very capable NoSQL stores that do their jobs very well, supporting massive scale out with low costs. However, they don’t replace high-quality SQL-based stores—they complement them. One day, SQL might be a thing of the past. A new system might be designed that completely replaces the traditional RDBMS. That day, however, is not now or even soon. SQL still presents a simple and reliable way to model data relatively naturally. That, combined with the massive explosion in data creation, is why the use of SQL is increasing and it won’t be dead any time soon.




