Recently, technology roles have become more generalized—cloud computing, for instance, requires a broader knowledge of technologies like storage and network. As technology has continued to evolve over the decades, many job positions have blurred into many roles or even morphed into new roles with new responsibilities.
One notable example I have seen in many organizations includes the situation where a
system administrator role has morphed into a
site reliability engineer (SRE) role. While this transformation typically applies to sysadmin roles, DBAs can also be included. In my previous role as a database architect, I was often tasked with ways to improve reliability of system level components with various forms of automation. This extended beyond the scope of the database to include components such as ETL processes, reporting and system maintenance, just to name a few.
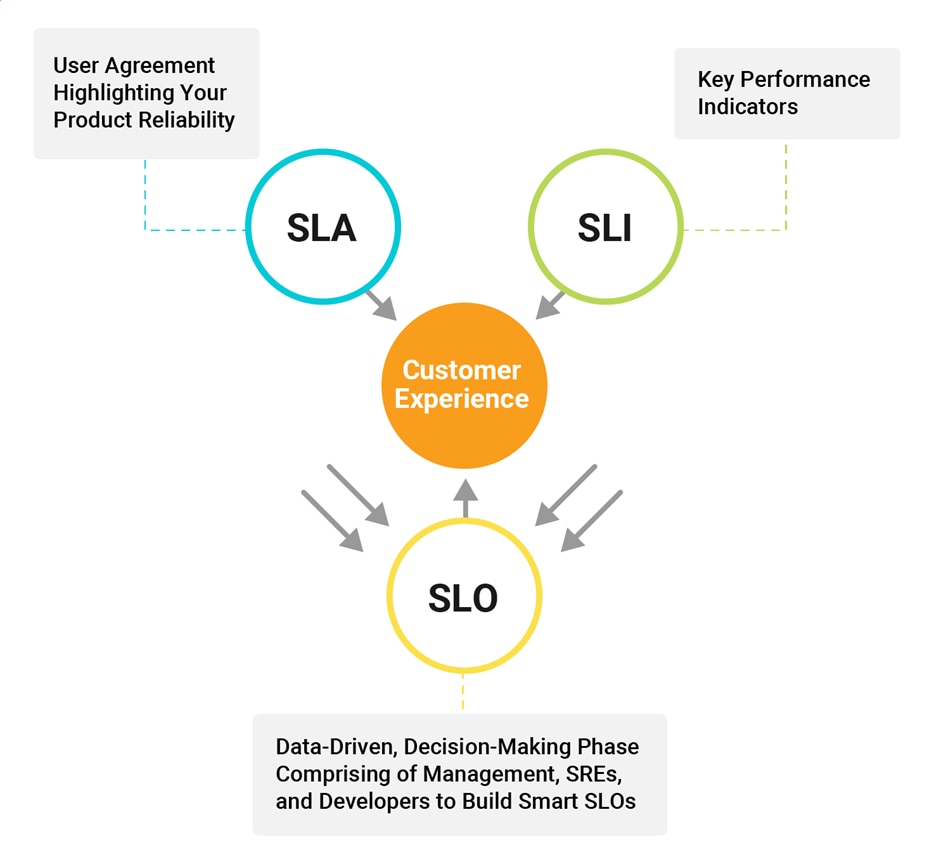
Though SREs may still perform the day-to-day duties of a systems administrator, they use different metrics to ensure availability through external-facing constructs like service-level agreements (SLAs) and service-level objectives (SLOs.) But what exactly are SLAs vs SLOs? As I explain below, while SLAs have been around for many years and are essentially contracts between organizations and consumers to ensure services meet defined expectations, SLOs can be considered a superset of SLAs and are to help ensure the underlying SLAs are met.
What Is the Purpose of SLAs?
SLAs are signed agreements between two parties. One party is an entity (usually a business) providing a service to a consumer. The consumer is essentially any consumer of the service being provided.
Most service providers require end users to acknowledge license agreements in which SLAs can be defined. The business agrees to ensure the service is made available for a certain amount of time, usually defined as uptime.
This is often referred to as the “availability of nines.” For example, a service offering 99% uptime is said to be at “two nines.” Three nines, or 99.9% uptime, equates to a calendar year, or 365 days. Any amount of downtime counts against the uptime and violates the SLA.
The SLA can dictate response times to meet customer expectations as well as other conditions. These conditions vary across service providers. For instance, response times can indicate how quickly IT staff will resolve a given issue.
When an incident occurs resulting in a decrease in uptime, an SLA may require a customer’s root cause analysis (RCA) as well as incident management during the course of the outage.
The agreement also has repercussions for the service provider if they don’t meet their obligations. These SLAs, especially in a cloud-based world, may include financial liability for any downtime the customer incurs. This can all be negotiated within the SLA.
In short, an SLA is a contractual “promise” from the service provider to its customers. Because of their contractual nature, SLAs are usually written by an organization’s legal team, whose sole focus is the legality of the agreement and protecting the provider.
These agreements are often not constructed with the IT teams responsible for meeting the SLA in mind. If the SLA promises something not easily attainable or if it’s promised without allocating the adequate budget to provide the promised availability, it can cause issues for IT staff. Every stakeholder involved with the SLA should communicate for the best possible outcome.
What Is an SLO?
Service-level objectives are key components of any defined service level agreement. These are usually agreed upon by all parties involved beforehand, and these components act as a means to measure the performance of the application offered by the service provider. In short, SLOs are the metrics that help determine whether the service provider has violated the agreed upon SLA.
What’s the Difference Between SLA and SLO?
SLOs are typically more stringent than SLAs and are internal markers not communicated to consumers. These strict requirements are designed so that if the objects are satisfied, then by default all SLAs will be automatically met.
SLA vs. SLO Example
For example, if an SLA provides for three nines of uptime (i.e., 99.9%) the service provider’s internal SLO may be 99.95%. If the service provider satisfies this objective, all subsequent SLAs are upheld. One important concept for an SRE is the “downtime budget.” This means other application tiers and services should expect all dependent services to be unavailable for their planned downtime and should handle those failures accordingly to reduce the risk of cascading failures.
What Is an SLI? SLI Example
Service-level indicators (SLIs) are what’s being measured in an SLO, which is the actual metric that must be met. The SLI must be met or exceeded for the SLO—and by default the SLA—to remain in compliance.
If the SLIs are missed, the effect flows downstream to both the SLO and SLA. SLIs can cover a wide range of metrics. For example, one of the more important ones is latency in terms of application response. In this case, a given application must respond within 10ms for a specific operation; otherwise, it fails to meet SLO tolerances.
How to Define an SLA vs. SLO—Common Challenges
Any organization that’s implemented an SLA or a corresponding SLO has undoubtedly faced numerous challenges. The language used in either agreement should be clear and concise, but this isn’t always the case
Given the legal nature of the SLA, the terminology can be nebulous. Any ambiguity in the document can cause confusion for both the consumer and service provider and potentially allow for loopholes capable of being detrimental to everyone involved. SLOs are typically easier to define, but they can still be cumbersome.
A major part of the difficulty can be defining—and subsequently tracking—metrics for either agreement. The key to implementing SLOs is simplicity and ease of use. Don’t overthink what’s needed and implement dozens of key performance indicators (KPIs), as this only adds complexity. Instead, identify a small set of metrics with the greatest business value you can easily implement for monitoring.
Solving SLA and SLO Challenges With Automation
I remember the days of using rudimentary means of tracking SLA metrics to ensure the agreement remained intact. Alerts would simply arrive as a number to call on a pager, which evolved into text or SMS messages and eventually email notifications.
Just as roles have continued to evolve, the ability to track the overall performance of any service architecture has as well. Furthermore, many organizations have continued to incorporate legacy systems, which require multiple integrations across the entire IT ecosystem to make things successful.
The more components you try to monitor, the harder it becomes to track overall performance. When these data points become more complex, the metrics become less meaningful and are likely to be pushed to the wayside or dropped.
Automation comes into play here because it helps facilitate easier gathering of specific metrics and sends prompt notifications to IT staff in the event of service times outside of operational parameters. It allows IT teams to quickly collect metrics, and combined with near-instant notifications of issues, it helps IT staff fix problems before SLA violations occur.
As organizations integrate more functionality, automation can swiftly deploy and incorporate appropriate monitoring into any process used for monitoring SLOs, thus safeguarding the underlying SLAs.
SRE teams use skilled technologists who know how to employ the use of various tools—including automation—to gather the appropriate metrics. This allows them to meet the ultimate goal of keeping the SLA intact.
How to Improve Service-Level Management
With organizations continuing to move forward in their digital transformation—and address the ongoing
integration of legacy systems to support hybrid IT with
cloud migration activities or the implementation of applications—it can be difficult to watch all the watchers, even with automation. Though automation can help with this, without a centralized solution to bring it all together, your environment can become difficult to manage and more prone to errors.
SolarWinds® Service Desk is designed to help you more easily set expectations around SLAs and provide visibility into service performance at scale. With automated alerting, ticket escalations, and other rule creation abilities, you can also more easily stay ahead of potential SLA breaches and implement more efficient workflows to help drive higher customer satisfaction scores.




