This is a story of using low-level kernel interfaces to optimize an edge case one of our agents encountered in some servers. The TL;DR version is that accessing
/proc/ can be very expensive if there are a lot of network connections, and the Netlink interface between userspace and kernel space is a much more efficient method.
Background
SolarWinds Database Performance Monitor (DPM) runs several agents, each specialized to a set of tasks. There’s one for gathering operating system metrics, called
vc-os-metrics. We capture per-process metrics in the same high resolution as all of our metrics, because in many cases a performance problem is due to a process causing collateral damage to another process by hogging resources. In addition to per-process metrics, we gather a lot of other things, like the usual memory, CPU, and disk metrics.
One of these global metrics is a variety of IPv4/6 socket statistics. Knowing what sockets are open, in which states, is vital for understanding what MySQL is doing, because MySQL is a networked process. Some of the typical conditions you might encounter include refused connections, which are often traceable to problems like an exhausted port range due to too rapid creatng and closing of sockets, that remain in
TIME_WAIT status and so on. A quick search for a phrase such as “tcp network tuning” will reveal how much there is to think about here, so obviously having socket statistics is important!
On Linux, the “standard” way to get this data is by parsing
/proc/net/tcp and
/proc/net/tcp6. These are pseudo-files in the proc filesystem (procfs), which exposes kernel data in a file-like structure so it can be accessed simply from userspace. This decouples utilities from kernel internals. (It’s so much nicer than the way we have to do things in FreeBSD, for example).
It turns out, though, that
/proc/net/tcp costs a lot to access. On some busy servers with a lot of sockets, which describes a lot of high-load MySQL servers, it
really costs a lot. In servers with 50,000 or so sockets, we saw it consuming so much system and user CPU time that the pseudo-file itself couldn’t be read in a single second. Not only is this a problem for the server — we don’t want to add load to the server — but it means that our agent couldn’t capture metrics at 1-second resolution, and we missed some metrics at some points.
Fortunately, there’s an alternative to the proc filesystem for this purpose.
Introduction to Netlink
Netlink is a way to do IPC between the kernel and a process, or between processes; it’s supposed to be a replacement for
ioctl in the future. It is implemented on top of BSD sockets, works in datagram mode and supports both unicast and multicast. There are various types of Netlink data that can be transfered between the kernel and user processes, and it’s extensible. Fortunately, socket status information is one of the built-in types, so there’s no need for us to extend it.
There’s a lot of information available on Netlink. You can read the authoritative
RFC for the gory details, or the
man page. The following might be better references, though:
Switching from /proc to Netlink
The beauty of
/proc/ files is how easy they are to work with. Our
/proc/ parsing code for TCP socket statistics was 20 lines of elegant, clean Go code. Using Netlink instead of Go introduces a lot more complexity. We had to write several hundred lines of relatively gnarly C code and integrate that with our Go code. We had to handle cases where the kernel doesn’t support this access; this doesn’t cause crashes, but we don’t get data, so we have to keep the old path as a fallback case. And finally we had to make the code observe itself in fine detail and rate-limit to make sure the old, expensive path doesn’t cause problems if we do fallback to using it.
The downsides, therefore, include:
- Complexity in code and debugging
- More complex build process
- Compatibility
- If there is a bug in the C code, it could break the agent badly.
The benefits, though, are compelling:
- From 100% CPU consumption (user and system) to less than 2% on highly loaded systems.
- A lot of the CPU consumption was in system CPU time. This was due to the access to
/proc and was reduced by using Netlink.
- A lot of CPU was also in user mode; this was reduced by using C code instead of Go. Go’s libraries for parsing strings into numbers aren’t all that efficient. We’ve seen this in other places as well, where we replaced
strconv.ParseFloat() and similar (including Scanf()) with more efficient alternatives that are less general but work for our use cases.
- Using C also reduced memory usage dramatically. Although that is not a problem per se, it matters a lot because it reduces Go’s garbage collection, which reduces CPU further.
- There’s a variety of things that are now cheap enough for us to consider gathering additional statistics in the future, though we haven’t done that yet.
It’s worth noting that Go does come with some Netlink support in
syscall/netlink.go. It is pretty bare-bones. We considered implementing what we needed in Go, but after some napkin math to estimate the amount of work the resulting code would have to perform, we decided that a C implementation would be way cleaner and faster.
Results
Of course, the proof is in the pudding. Here’s a screenshot of our Agent Dashboard on two servers that are similarly highly loaded. Over the three-day period shown in this screenshot, you can see the overall average CPU and memory consumed by the agents. The first agent was upgraded about 3/4ths of the way through this period.
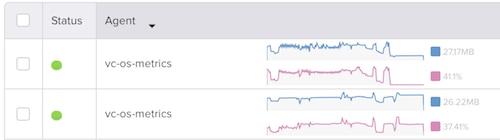
So, again, the overall impact was to avoid periodically hitting 100% CPU (and missing some deadlines) to a rock-steady 2% CPU; memory reduced from 30MB to 11MB.
We’ve had this deployed on our customers’ machines for many weeks now. We had an initial problem with failure to capture metrics on a specific kernel version, but were able to diagnose that quickly and make it compatible with all kernels our customers are running. (We’ll keep an eye on this in the future, but we don’t expect any further problems.) Otherwise, it’s been smooth sailing and was well worth the effort.
If you’re not yet experiencing the benefits of insanely detailed per-process and per-query metrics, as well as thousands of other metrics, all in a beautiful dataviz-rich UI that shows exactly what’s going on,
contact us for a personalized demo, and we’ll be glad to show you what you’re missing.






