
Choosing the Right Database
This is a natural question that many will ask: Which database do I want? Time will be spent trying to determine which database is the right database. The truth is that your application systems are complex, and when broken down, you will find that different pieces are best served by different database engines. Netflix is a great example of this, as they use a handful of database engines to process the billions of data points they collect and analyze daily. So, set aside the idea that you are going to find the one true database that is better than everything else. Start thinking about how you can find the right database for different pieces of your complex systems. Now, let’s look at how you can make an informed decision as to the database engine that will work best for your needs.CAP Theorem
CAP stands for Consistency, Availability, and Partition tolerance. The theorem states that you cannot have all three, as there are natural tradeoffs between the items. Similar to “fast, cheap, and easy, pick two,” people say about CAP: “consistency, availability, or partition tolerance, choose two.” Consistency means that any read request will return the most recent write. But as we have discussed earlier, consistency need not be immediate. Our requirements could be satisfied with a state of eventual consistency. This graph helps explain the different consistency levels.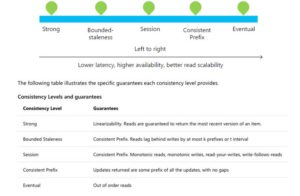
From: https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
Availability means that a non-responding node must respond in a reasonable amount of time. This is different than partition tolerance, which states the system will continue to operate despite network or node failures. When you put these three items together, you should start to understand why you can only ever prioritize two of them at a time. For example, if your system needs to be available and partition tolerant, then you must be willing to accept some latency in your consistency requirements. Here’s what the CAP theorem looks like: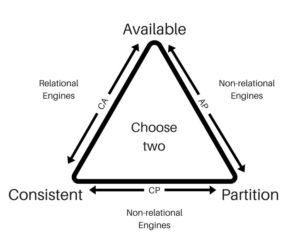 Let’s look at each side the triangle above (labeled CA, AP, and CP). Traditional relational databases are a natural fit for the CA side. That is, they can feature strong consistency and be highly available, but often at the expense of partition tolerance.
Non-relational database engines are meant to satisfy AP and CP requirements. This is why we have so many flavors of NoSQL: key-value, document, and graph, to name a few. We have two sides of the triangle supported by NoSQL database engines. That means we have a large variety of availability and partitioning requirements along with specific query and workload requirements. It is easy to understand why we have so many NoSQL solutions available.
As a very general classification, you could think of things this way: relational databases are optimized for writes, and NoSQL databases are optimized for reads. That’s not an absolute for each engine, just a generalization to understand why the engines were originally built.
Let’s look at each side the triangle above (labeled CA, AP, and CP). Traditional relational databases are a natural fit for the CA side. That is, they can feature strong consistency and be highly available, but often at the expense of partition tolerance.
Non-relational database engines are meant to satisfy AP and CP requirements. This is why we have so many flavors of NoSQL: key-value, document, and graph, to name a few. We have two sides of the triangle supported by NoSQL database engines. That means we have a large variety of availability and partitioning requirements along with specific query and workload requirements. It is easy to understand why we have so many NoSQL solutions available.
As a very general classification, you could think of things this way: relational databases are optimized for writes, and NoSQL databases are optimized for reads. That’s not an absolute for each engine, just a generalization to understand why the engines were originally built.





