I’ve heard repeatedly from people in this industry that what we need is a single interface to our infrastructure. For status monitoring, perhaps that’s best represented by the ubiquitous “Single Pane of Glass” (Drink!); for general network management, perhaps it’s a Manager of Managers (MoM); and for infrastructure configuration it’s, well, that’s where it gets tricky.
Configurator of Configurators
OpenConfig
I was once hopeful of a future where I could configure and monitor any network device I wanted using a standardized operational interface, courtesy of the efforts of
OpenConfig. If you’ve not heard of this before, you can check out an
introduction to OpenConfig I wrote in early 2016. However, after a really promising start with lots of activity, OpenConfig appears to have gone dark; there are no updates on the site, the copyright notice still says 2016, the latest “News” was a 2015 year-end round-up, and there’s really little to learn about any progress that might have been made. OpenConfig is a mysterious and powerful project, and its mystery is only exceeded by its power.
SNMP Mk II?
I mention OpenConfig because one of the biggest battles that project faced was to to reconcile the desire for consistency across multiple vendors’ equipment while still permitting each vendor to have their own proprietary features. Looking back, SNMP started off the right way too by having a standard MIB where everybody would store, say, network information, but it became clear quite quickly that this standard didn’t support the vendors’ needs sufficiently. Instead, they started putting all the useful information in their own data structures within an Enterprise MIB specific to the vendor’s implementation. Consequently, with SNMP, the idea of commonality has almost been reduced to being able to query the hostname and some very basic information. If OpenConfig goes the same way, then it will have solved very little of the original problem.
Puppet faces a similar problem in that its whole architecture is based on the idea that you can tell any device to do something, and not need to worry about how it’s actually accomplished by the agent. This works well with the basic, common commands that apply to all infrastructure devices (say, configuring an access VLAN on a switchport), but the moment things get vendor-specific, it gets more difficult.
The CoC
It should therefore be fairly obvious that to write a tool that can fully automate a typical homogeneous infrastructure (that is, containing a mix of device types from multiple vendors) is potentially an incredibly steep task. Presenting a heterogeneous-style front end to configure a homogeneous infrastructure is tricky at best, and to create a single, bespoke tool to accomplish this would require skills in every platform and configuration type in use. The fact that there isn’t even a common transport and protocol that can be used to configure all the devices is a huge pain, and the subject of another post coming soon. But what choice do we have?
APIs Calling APIs
One of solutions I proposed to the silo problem is for each team to provide documented APIs to their tools so that other teams can include those elements within their own workflows. Most likely, within a technical area, things may work best if a similar approach is used:
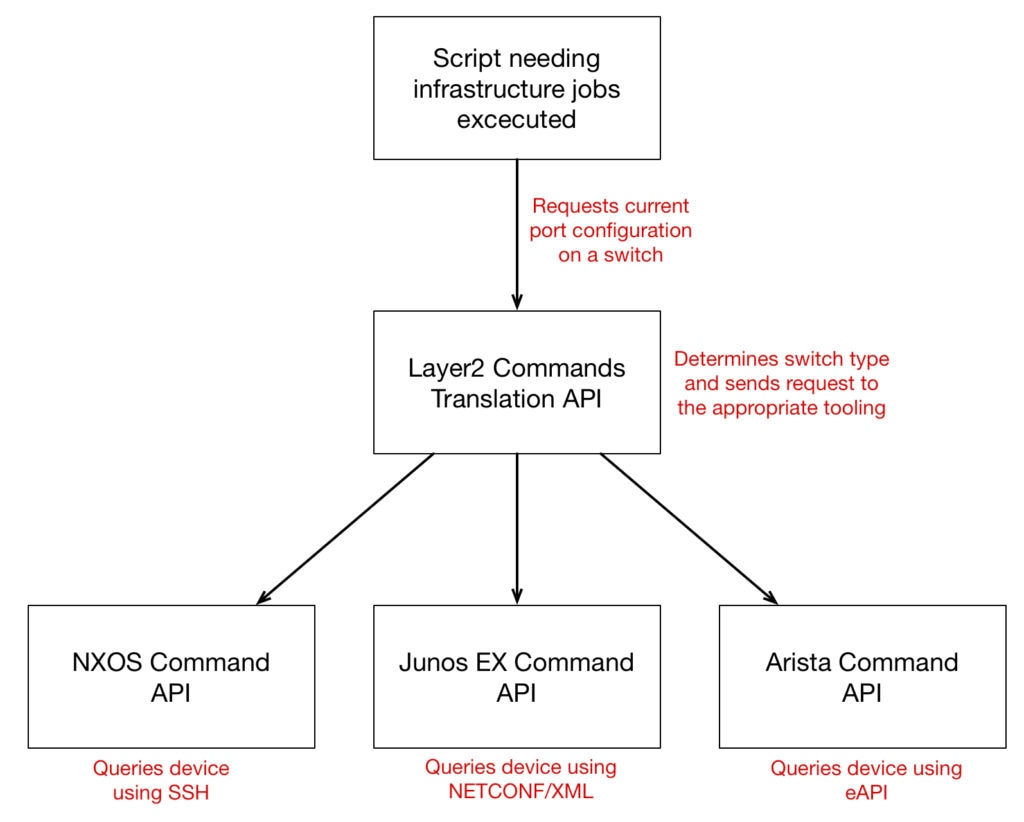
Arguably the Translation API could itself contain the device-specific code, but there’s no getting around the fact that each vendor’s equipment will require a different syntax, protocol, and transport. As such, that complexity should not be in the orchestration tools themselves but should be hidden behind a layer of abstraction (in this case, the translation API). In this example, the translation API changes the Cisco spanning-tree “portfast” into a more generic “edge” type:
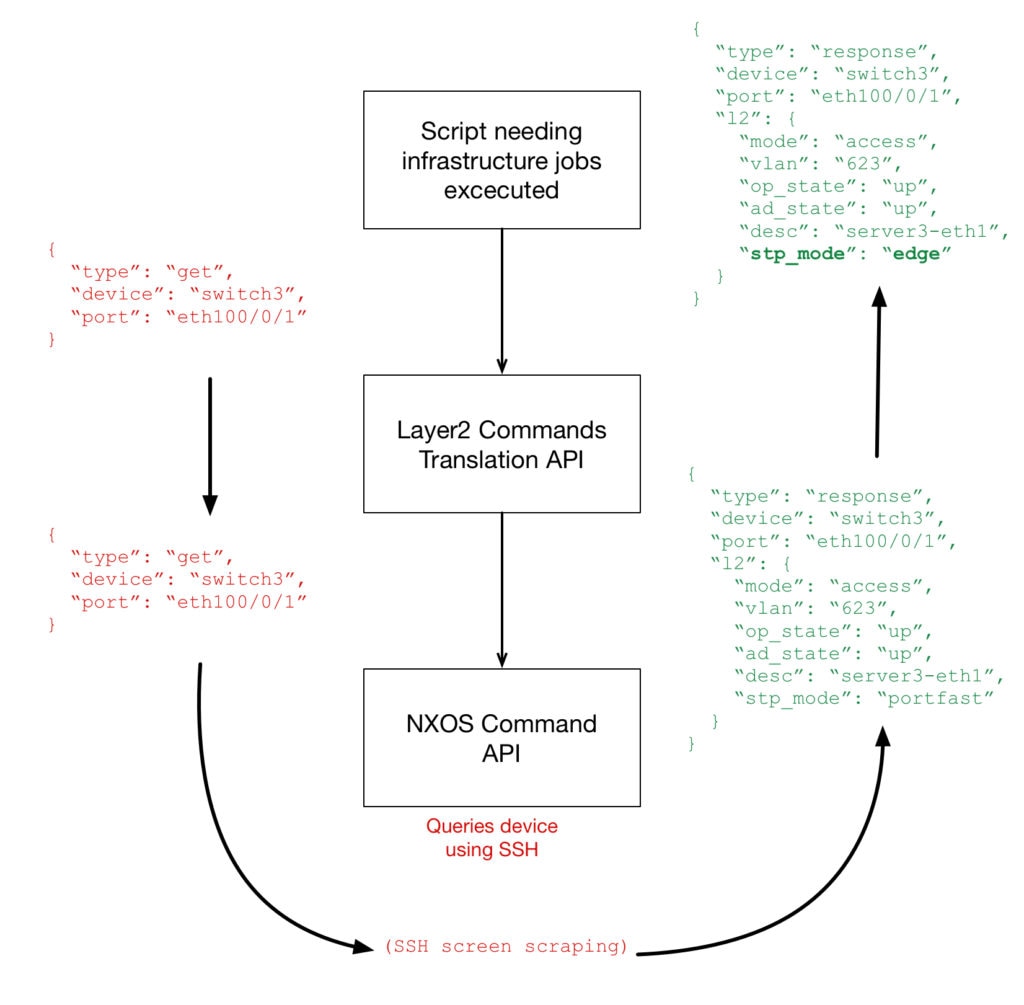
There’s also no way to avoid the exact problem faced by OpenConfig, that some vendors, models, features, or licenses, will offer capabilities not offered by others. OpenConfig aimed to make this even simpler, by pushing that Translation API right down to the device itself, creating a
lingua franca for all requests to the device. However, until that glorious day arrives, and all devices have been upgraded to code supporting such awesomeness, there’s a stark fact that should be considered:
Most automation in homogeneous environments will, by necessity, cater to the lowest common denominator.
Lowest of the Low
Let’s think about that for a moment. If we want automation to function across our varied inventory, then the fact that it ends up catering to the lowest common denominator means that it should be possible to deploy almost any equipment into the network, because the fancy proprietary features aren’t going to be used by automation. While that sounds dangerously like ad-copy for white box switching, the fact remains that if any port on the network can be configured the same way (using an API) then the reality of which hardware is deployed in the field is only a matter of whether or not a device-specific API can be created to act as middleware between the scripts and the device. That could almost open up a whole new way of thinking about our networks...
Abstract the Abstraction
Will we end up dumbing down our networks to allow this kind of heterogeneous operation of homogeneous networks? I don’t know, but it seems to me that as soon as there’s a feature disparity between two devices with a similar role in the network, we end up looking right back at the LCD.
I’m a fan of creating abstractions to abstractions, so that—as much as possible—the dirty details are hidden well out of sight. And while it would be lovely to think that all vendors will eventually deploy a single interface that our tools can talk to, until that point, we’re on the hook to provide those translations, and to build that common language for our configuration and monitoring needs.
Qu'est-ce qui pourrait mal se passer?






