Databases have a kind of iron triangle for specific types of query plans, whereby they can pick between two out of three things but can’t get all three of them. (The “iron triangle” we’re all most familiar with is “good, fast, cheap—pick any two.” This post is a play on that phrase.)
In databases, the iron triangle would be “no sorting, no indexing, no temporary storage: pick any two.” Let’s dig into what this means, types of queries this applies to, and what it means for you when you're designing queries and indexes.
What Is The Iron Triangle?
The iron triangle is the combination of three things, which are really desirable when the database is trying to execute a query efficiently and fast. Ideally, the database would like to avoid the following three things:
- Don't Sort. The database wants to avoid sorting data, because it's relatively slow and costly compared to not sorting data. But if the query needs ordering—for example it uses an ORDER BY that says the data needs to be sorted—the only way the database can avoid sorting is if there's an index on the data, sorted in the specified order already. For example, if the query says ORDER BY A, B then there needs to be an index defined like INDEX(A, B) or the database will have to sort the data somehow.
- Don't Index. The database and/or the engineer would like to avoid creating indexes on data, generally. Indexing can mean maintaining another copy of the data, which is a) duplication and b) extra work any time the data changes.
- Don't Use Temp Storage. If the data needs to be sorted and there's no index, the only other choice is some type of temporary storage. This can be a temporary table, a hash table, a temporary file, a temporary buffer in memory—and in fact an index is a type of temporary storage. The main thing about temporary storage is it's duplicating the data so it can be ordered, which is one of the things an index can do. From the conceptual point of view, when you have an index and you insert a row into a table, the index is storing it until it's needed in a SELECT later, which is a kind of very longterm, reusable temporary-ness.
The iron triangle's concepts are kind of fuzzy and intermingled, as you can see, but in general the point is that you can't always get all the things you want without also accepting some of the things you don't want.
What Queries Suffer From The Triangle?
This catch-22 situation usually applies to queries that are expressing a question that has a few different combinations of filtering and ordering criteria together—usually more complicated analytical queries, although quite simple queries can also be subject to these mutually exclusive conditions.
One key thing to know is that it's not only ORDER BY queries that can be solved with sorting data, and therefore can benefit from an index with a usable native ordering. It's also lots of types of grouping queries, including GROUP BY and DISTINCT types of queries. That's because these queries are often most efficient if the data in each group can be processed one group at a time, batching each group up without needing to keep a lot of groups. If the database can do a group at a time, it doesn't need to allocate temporary storage to hold lots of unfinished groups (see? temporary storage again!).
A lot of times the dilemma comes from several parts of the query either requiring, or benefiting from, data that's in sorted order. For example, a query that has an ORDER BY and a GROUP BY. Fortunately, if these operations need the data in the
same sorted order things can go pretty well, but unfortunately that's often not the case, and perhaps one of them can be optimized by using an index but the other will have to resort to temporary storage to get the job done.
Here's an example question: how many meetups did each member attend in 2018? Imagine a "pure" data model, perfectly normalized without duplication, and without indexes. For example, imagine you were doing this with CSV files, one of members and one of attendance records. The query might look like this:
select member.name, count(*)
from members inner join attendances on member.id = attendances.member_id
where attendances.date = 2018
group by member.name
order by member.name;
The database has a couple of choices for how to execute that. It can iterate through each member and then go count how many matching attendances there were—which is a full scan of all rows in attendances. Or it can pre-group the attendances, and then join in the matching members.
If it scans the members and counts matching attendances, it needs to sort the members before or after doing so, unless it has an index.
If it pre-groups the attendances, it needs to sort them or keep a hash table of them, unless it has an index. And even if it does pre-group them, it'll still have to sort them somehow to return them ordered by member name.
Understanding Optimizer Choices
My example in the previous section is really naive, because most databases have an optimizer/planner that has better algorithms than that. In fact, sophisticated databases like PostgreSQL have lots of fancy algorithms they can use, many of which take quite a while to study and understand.
That's actually part of the reason this is tricky: databases have so many complicated ways they can potentially execute queries, and the optimizer/planner has to consider them and predict how costly it would be to execute them. It does this using statistics and very complicated methods, which often can't be deterministic or exhaustive because the cost of considering all the possibilities is actually factorial. So the optimizer makes a choice, and it can often be really hard to figure out why it did the "wrong" thing so you can fix it.
Examining Sample EXPLAINs
This is where EXPLAIN is super helpful, because it can help you trace the optimizer's decision-making. EXPLAIN is different for every database, but it's
the key tool in improving query execution plans. A couple of things make EXPLAIN hard to use beyond just needing to learn how to interpret it, though: you have to have real, representative samples of real queries running against real data in production; and you have to have actual EXPLAINs from those queries at the exact time that they ran. It's important to get real EXPLAINs at the time that they run because the "parameters" in the WHERE clause, as well as the exact data in the tables at the time the query runs, influence how the query is planned. As the data changes, or if the query is run against the 2017 data instead of 2018, or for different users or whatnot, the optimizer/planner will make different choices. So you can't just go back later and run EXPLAIN with a different sample query and always get the right answer about the optimizer's choices.
There's a few ways to get real samples with realtime EXPLAIN, and they vary depending on your database. For example, PostgreSQL has an auto-explain feature that can log slow queries to the log along with their EXPLAIN, which is great.
Not every database makes it so easy, but fortunately, tooling can help. At SolarWinds® we deal with this by capturing sample queries using advanced algorithms that ensure you have a rich set of samples that are representative—not just the slowest query, which is a skewed view and can lead you to optimize for an edge case that'll hurt the majority of other queries.
As a bonus, there's a visual UI that helps you plot query examples and explore them with your mouse, seeing the EXPLAINs easily. Here's a gif while I'm on the topic.
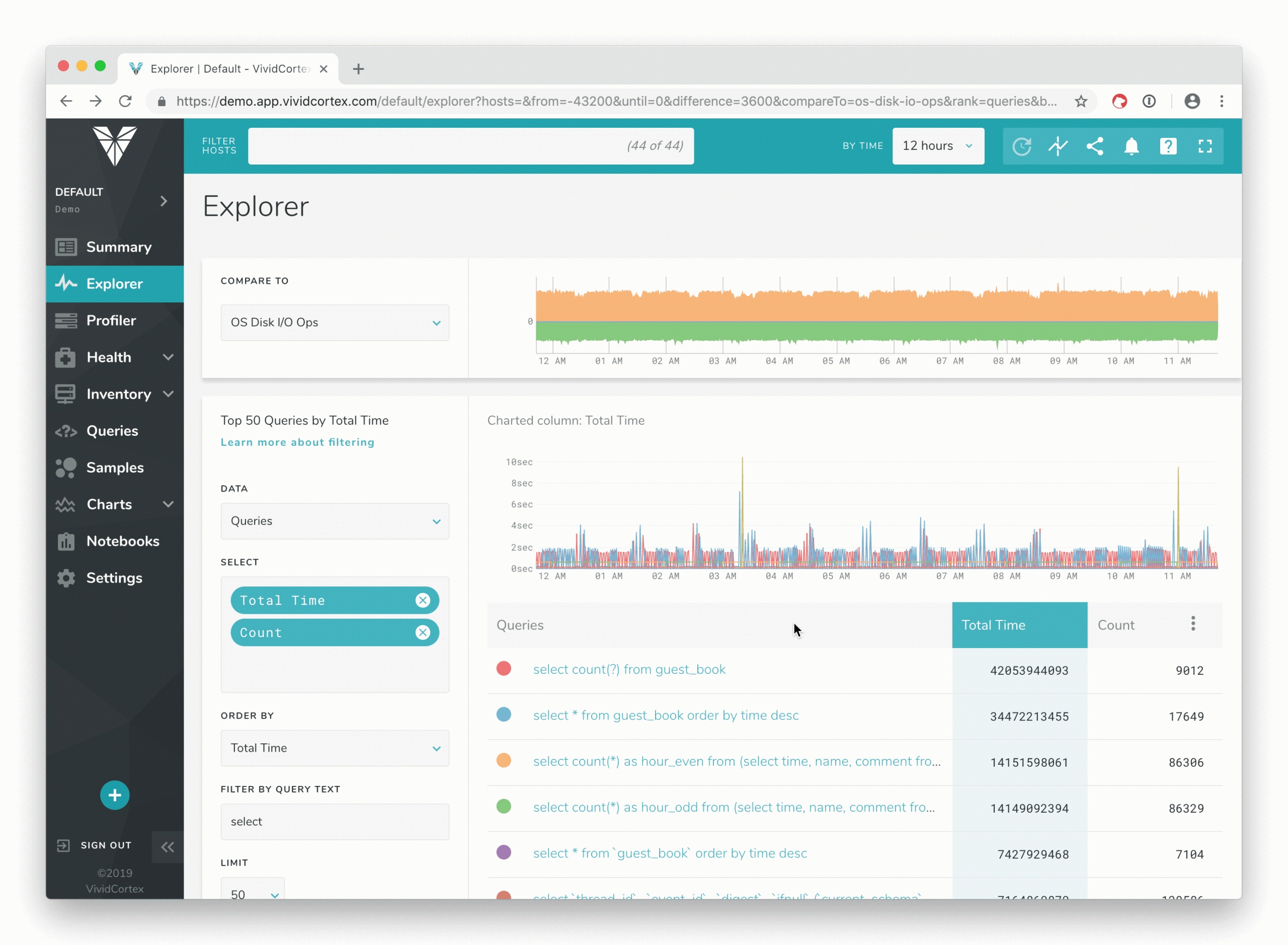
Imagine trying to explore samples without the UI—would you know there was such an obvious pattern in the latencies? How would you get EXPLAINs and compare between fast and slow queries easily if you didn't have this in a web browser? You'd need to get access to the server, get its log, analyze the log, and then go through it manually. In cases where you're trying to discover and fix black-box optimizer behavior, the SolarWinds® Database Performance Monitor UI can save hours of work.
Conclusions
In conclusion, keep in mind that although databases are pretty close to magic, they still can't break the speed of light or other laws of nature such as "data can only be sorted in one direction at a time." And that's really what the iron triangle expresses—so when you have a query that needs several types of sorting and grouping together, you should be ready for the possibility that you'll need a combination of different indexes to make it faster, and/or perhaps even it's not possible to satisfy all of the needs with any combinations of indexes, so the database will have to resort to sorting or temporary storage to execute the query. Happy optimizing!





