Some of the best-selling books of all time are self-help books. Reading about the potential for change always intrigues people enough to buy the book. To succeed in enacting positive change, you must do just that—change. People’s habits are familiar and safe, and change requires effort down an unknown path. People aren’t sure of the outcome, and as a result, usually stick with the proven method—even if it’s what they’re trying to change.
With most self-help books, the problem is easily identified—but resolution requires effort. The solutions discussed must be applied to the person’s everyday behavior. If the solution doesn’t apply to the person’s specific issue, the improvement process stops.
In a more-perfect world, a person would receive real-time feedback regarding how such a solution improves their current situation. This direct feedback would allow the person to understand if they should go through with the solution. While this real-time mechanism doesn’t exist for self-help books (yet), it exists for data. DataOps is the data engineering methodology built to provide such feedback to your data processes and pipelines.
Data engineers are aware of the inefficiencies and manual tasks within their data estate. The various IT silos don’t communicate effectively (or at all), and tooling specific for one task precludes another team’s visibility. As a result, the quality and value of the data being delivered to end users is well below expectations. This hurts the software’s effectiveness and the end user’s satisfaction.
Data engineers are also aware of how data source integration is haphazard, manual, and often problematic. And when some facet of the data pipeline changes, causing performance to randomly slow down, the end users become unhappy. But uncertainty whether a process change will lead to significant improvements and the cost of allocating time to change the process make it difficult for management to justify the change.
In other words, management is in the bookstore, reading the self-help book, reviewing the solutions, but can’t or won’t pull the trigger on taking the actions necessary to create a positive change.
This is where DataOps comes to the rescue. DataOps provides reusable building blocks for data development and integration, automation to ensure data is accurate, and monitoring at all lifecycle stages to help maintain and improve performance and efficiency of data delivery. With DataOps, we introduce observability at each stage of the data engineering process, providing feedback loops and allowing teams to identify issues and correct them quickly.
DataOps provides effective monitoring and orchestration feedback to all facets of the data engineering process at each stage of the data lifecycle—from the sourcing of the data through development to delivery of the application to the end user—so these processes can take advantage the feedback loops to form a continual loop of communication and improvement across components and processes.
Figure 1 shows the data engineering pipeline process across the top, and the feedback from DataOps across the bottom.
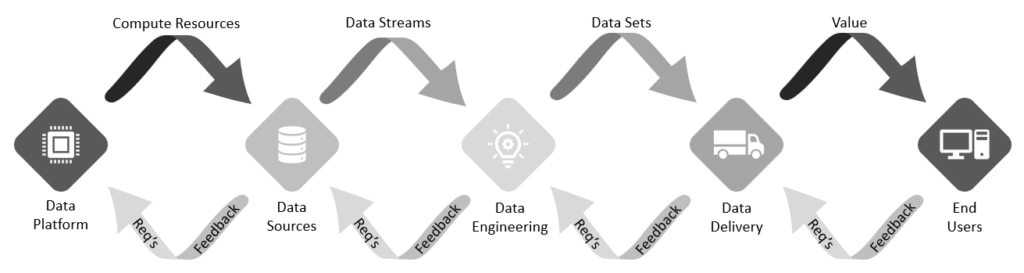
Figure 1: Data engineering workflow with DataOps feedback
Effective tooling is necessary to facilitate this feedback. SolarWinds has powerful and useful tools in this space designed to dramatically improve the feedback loop.
- SolarWinds® Database Mapper to map and document data sources, build data dictionaries, and track documentation changes.
- SolarWinds Task Factory to introduce reusable and predictable data integration components to streamline the data integration processes. Task Factory helps dramatically accelerate the creation of data pipelines, improve data quality by taking the mystery out of data pipeline source components, and reduce human error by automating what would otherwise be manual tasks.
- SolarWinds SQL Sentry to monitor performance throughout the DataOps process by providing observability and exposing feedback loops to make sure efficiency is maintained.
Almost every data engineering processes can be improved. Change is not only possible but necessary to help boost your organization’s competitive advantage. Implementing DataOps can be difficult, unless you have the right tooling. But with the right tooling in place, your IT organization can quickly adopt and implement DataOps, improve observability at each layer of the DataOps process, strengthen data quality, and deliver heightened business value to your end users.






