Silos in IT should be a construct of the past. Tight, rigid, and insulated IT silos were an unintentional design flaw of many IT organizations worldwide over the last few decades. Corporate teams would work on their respective piece of the puzzle in isolation, actively completing their tasks, but having little to no input or conversation on how their output contributed to the greater good. When you lay out the flow, it looks something like
Figure 1.
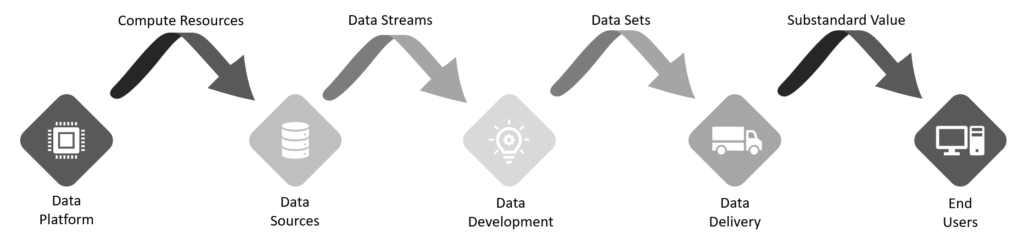 Figure 1: Traditional data engineering workflow
Figure 1: Traditional data engineering workflow
The data platform team provides a functional base for everything to run on, including physical and virtual servers, storage, and networking, so it all can communicate. Integration-focused teams would provide the sources of data that feed into development. Data developers would then take these data sources and extract the meaning of the data, so the application can process it. The application would finally take this data feed and deliver it to the end users.
This process harbored a problem, though: the quality of the software experience for the end users started to degrade. Different software engineering methodologies were created to help remedy this situation and improve the quality and speed of the software releases for data delivery. However, data engineering—the act of integrating, storing, and retrieving data efficiently and accurately—has not kept up. The process of managing and transforming the data behind these critical applications is still nascent.
DataOps is an emerging methodology designed to bring the best points of several software development methodologies to data engineering and to deliver improvements to data management practices. DataOps delivers two layers of improvement:
- It automates and streamlines certain tasks, such as command unit tests and integration frameworks
- It generates analytics and monitoring on an ongoing basis to reveal query performance and resource consumption
DataOps Goals
The primary purpose of DataOps is to provide real-time analytics on the entire data lifecycle, generating feedback the development process can embrace to improve the quality and efficiency of data processing and delivery.
The first step in DataOps is to push the IT organization to embrace a new mindset that can exploit these analytics and collaborate to make the data engineering process as efficient as the software engineering process. After this shift in mindset, tooling can be introduced to help it along.
One of the goals of DataOps is to provide a foundation to ensure an application, no matter what stage it occupies in the software development lifecycle, delivers consistently accurate data. Unit testing should automatically validate database commands to boost deliverable data quality.
Manual or nonrepeatable data integration processes are also prime candidates for improvement. Reusable integration frameworks not only make integrating with dissimilar data sources straightforward and repeatable but allow for expected and consistent processes that save time and reduce the potential for human error.
Finally, ongoing monitoring of the holistic data platform state at the macro level, as well as command performance trends on the micro level, allow for real-time feedback on system state and changes in expected command behavior. Code that degrades performance, consumes too much CPU or RAM, or performs much slower than previously can be identified during the development process and quickly corrected. The availability of feedback throughout the development cycle is illustrated by Figure 2.
 Figure 2: Data engineering workflow applying DataOps methodologies
Figure 2: Data engineering workflow applying DataOps methodologies
Help Is Available
For all its benefits, however, DataOps is not often adopted. One key reason is it’s challenging and time-consuming to get started.
SolarWinds can help there. Its
DataOps product suite can boost your data engineering processes to help you improve your competitive advantage. Here’s what each component offers:
- SolarWinds Database Mapper helps to validate and analyze the changes to your data platform over time.
- SolarWinds Task Factory offers a reusable data integration framework designed to ensure efficient ETL processes.
- SolarWinds SQL Sentry monitoring tool provides both macro-level and micro-level monitoring of your SQL Server platform, so you can improve the performance of the commands in development and maintain this performance once the code is released.
These three products, when used as part of an operational change in your IT department to improve the data engineering practices, will help your organization use these complex data platforms to its fullest potential. Not only can you help data development and engineering move at the speed of the software development, but you can improve the quality of the data throughout the entire process.

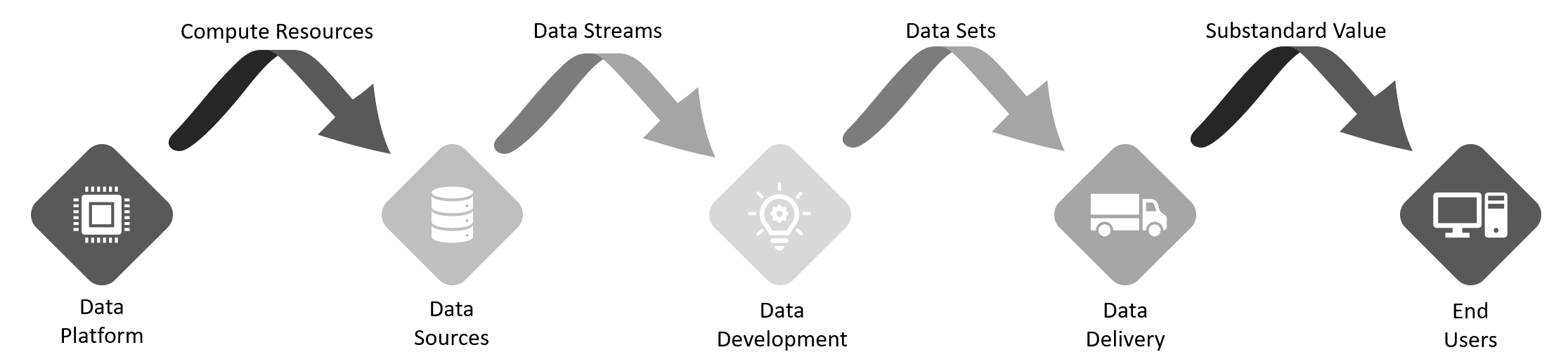 Figure 1: Traditional data engineering workflow
The data platform team provides a functional base for everything to run on, including physical and virtual servers, storage, and networking, so it all can communicate. Integration-focused teams would provide the sources of data that feed into development. Data developers would then take these data sources and extract the meaning of the data, so the application can process it. The application would finally take this data feed and deliver it to the end users.
This process harbored a problem, though: the quality of the software experience for the end users started to degrade. Different software engineering methodologies were created to help remedy this situation and improve the quality and speed of the software releases for data delivery. However, data engineering—the act of integrating, storing, and retrieving data efficiently and accurately—has not kept up. The process of managing and transforming the data behind these critical applications is still nascent.
DataOps is an emerging methodology designed to bring the best points of several software development methodologies to data engineering and to deliver improvements to data management practices. DataOps delivers two layers of improvement:
Figure 1: Traditional data engineering workflow
The data platform team provides a functional base for everything to run on, including physical and virtual servers, storage, and networking, so it all can communicate. Integration-focused teams would provide the sources of data that feed into development. Data developers would then take these data sources and extract the meaning of the data, so the application can process it. The application would finally take this data feed and deliver it to the end users.
This process harbored a problem, though: the quality of the software experience for the end users started to degrade. Different software engineering methodologies were created to help remedy this situation and improve the quality and speed of the software releases for data delivery. However, data engineering—the act of integrating, storing, and retrieving data efficiently and accurately—has not kept up. The process of managing and transforming the data behind these critical applications is still nascent.
DataOps is an emerging methodology designed to bring the best points of several software development methodologies to data engineering and to deliver improvements to data management practices. DataOps delivers two layers of improvement:
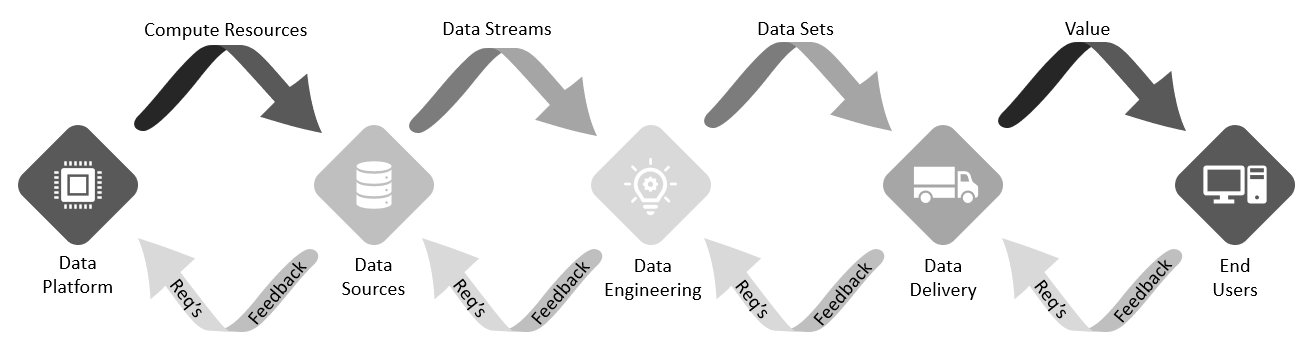 Figure 2: Data engineering workflow applying DataOps methodologies
Figure 2: Data engineering workflow applying DataOps methodologies





