A data warehouse (DW) is a centralized repository of data integrated from multiple systems.. This data is often cleansed and standardized before being loaded. Designed to support analytical workloads, a data warehouse can help organizations better leverage both current data and historical data to improve decision-making through the analysis of business processes and outcomes.
In addition to DW, you may also see terms like enterprise data warehouse (EDW) and data marts used to describe these data repositories. Organizations may have an EDW as well as several data marts. The EDW provides consolidated data from across the enterprise and acts as a source for the data marts, which contain a subset of the EDW data specific to a team or process. Another common option is to build an EDW and multiple analytical models or OLAP cubes that contain subsets of the data warehouse tables to provide additional features for faster query performance or complex data calculations.
Have you ever struggled to integrate data from multiple systems to get a holistic view of a process? In this guide, I’ll discuss why a data warehouse can help improve this situation.
Key Benefits of a Data Warehouse
Let’s say you work at a company producing widgets and gizmos, and the marketing department plans a promotion on widgets. The promotion information is entered into the point-of-sale system. The inventory planning system is updated in anticipation of increased sales. The results of the promotion are in the sales system. Manually pulling data from the different sources of marketing, point-of-sale, inventory, and sales operations systems would take significant effort. You could instead schedule loads from the four systems into a data warehouse automatically. The data load process would cleanse and integrate the data, then organize it into a read-optimized format in the data warehouse, allowing you to query one system to see the entire process and effect of the promotion on widgets.
In addition to consolidating data from many sources, data warehouses can move the analytics workload off the transactional (OLTP) data stores, which can help improve the performance of the transactional systems. Analytical queries are fast in a data warehouse because the data is modeled for fast reads.
Data warehouses can also maintain data availability even as source data is archived and source systems are replaced. Also, data warehouses can improve consistency in terminology and naming conventions and the standardization of data values from disparate sources to help ensure data quality.
Common Types of Data Warehouse Architectures
Data warehousing has been a staple of integrated organizational reporting for about 30 years, but the technologies used have changed over time. Although some newer Big Data technologies are starting to change the norms, data warehouse architectures have primarily remained the same. Generally, raw data is acquired from source systems, staged for transformation, loaded into the data warehouse, and queried with structured query language (SQL). How the data is stored depends on the approach taken.
There are three popular approaches for storing data in a data warehouse:
- Ralph Kimball’s dimensional approach
- Bill Inmon’s normalized approach
- Dan Linstedt’s data vault approach
I’ll discuss some of the key differences between these database architecture models below.
Dimensional Models
The dimensional approach uses a star schema, which organizes the lowest level of available data into facts and dimensions. Facts are tables that hold the measurable quantitative data about a business process, while dimensions contain descriptive attributes used to group or slice the fact data. Facts are related to dimensions through foreign keys that relate to the primary key of the dimension table. The primary keys in the dimension tables are often surrogate keys — sequentially assigned integers — rather than natural keys that come from the source systems. These surrogate keys allow you to add values to a dimension table for “unknown” or “not applicable” dimensions and replace data sources.
Fact tables are usually designed in third normal form, while dimensions are designed in second normal form. This differs from an operational database, which is generally entirely third normal form. This difference optimizes the data warehouse for analytical workloads compared to an operational database, which is optimized for write workloads. The queries against the dimensional model are simpler (fewer joins), and many metrics are simple aggregates (sum, average, maximum) of columns in the fact tables.
In Kimball’s approach, reports and end users directly query this data warehouse. The decisions made while transforming and cleansing disparate data may result in changes in data values or source data being excluded as the data is loaded into the dimensional model. The dimensional model enforces assumptions about how the business wants to analyze the data.
I’ve been building data warehouses for over 15 years, and most of them have used the dimensional approach because it reduces complexity in the data model and optimizes usability for reports, dashboards, and self-service business intelligence users.
Normalized Models
In the normalized approach, tables are primarily stored in third normal form. Tables represent entities, which are then grouped into subject areas. On top of the normalized data warehouse are dimensional data marts containing summarized data, usually aligned to a department or function.
If analysts need data unavailable in the summarized dimensional data mart, they can query the normalized data warehouse to get the required data. This approach makes it very easy to write data to the data warehouse. However, querying normalized data warehouse often requires more complex queries.
Data Vault
Data vault modeling uses a structure containing hubs, links, and satellites to provide a single version of truth. The data is not cleansed or conformed to business requirements before being stored. Hubs contain business keys, surrogate keys, and a source system indicator.
A link table in a data vault contains surrogate keys of two or more hub tables to represent associations between business keys. Satellite tables contain metadata linking them to their parent hub or link, metadata about the association and attributes, and start and end dates for the attribute.
This data vault storage layer is not optimized for analytics, so creating a dimensional model on top of the data vault is a very common method used to support analytics needs.
How Does Data Integration Work
Data warehouses are typically loaded in batches or micro-batches. Multiple records are collected before being processed together in a single operation. Data integration processes are often categorized as either ETL (extract, transform, load) or ELT (extract, load, transform). The difference is where the processing takes place. In ELT, the data is loaded into the data warehouse and then transformed. In ETL, the data is transformed, usually in-memory, and then loaded in the data warehouse.
Most of the data warehouses I build today are in Azure (SQL Server or Synapse) and use Azure Data Factory (ADF) to populate the data warehouse. For smaller data warehouses, it’s straightforward to use ADF to copy data from the sources to the DW and then call stored procedures to populate the dimensional model. This is an example of ELT. Your data loads do not have to be strictly ELT or ETL.
Building a SQL Server in and migrating a data warehouse environment to Azure? Watch this webinar for some helpful first-hand learnings:
What to Know About Modern Data Warehouses
Data warehouses are traditionally created in a relational database and receive data through batch loads, but the modern data warehouse expands beyond those practices. Modern data warehouses often still use relational databases, but they may have a massively parallel processing (MPP) engine to support querying large amounts of data sets—which can contain both structured and unstructured data. Also, many data warehouse technologies have been optimized to receive real-time or streaming data.
As illustrated below, data warehouses may be paired with raw data captured in a data lake to provide:
- Faster, less expensive staging of data as it is processed and loaded to the data warehouse
- Less expensive archived storage data
- Data virtualization features to query semi-structured data from the data warehouse
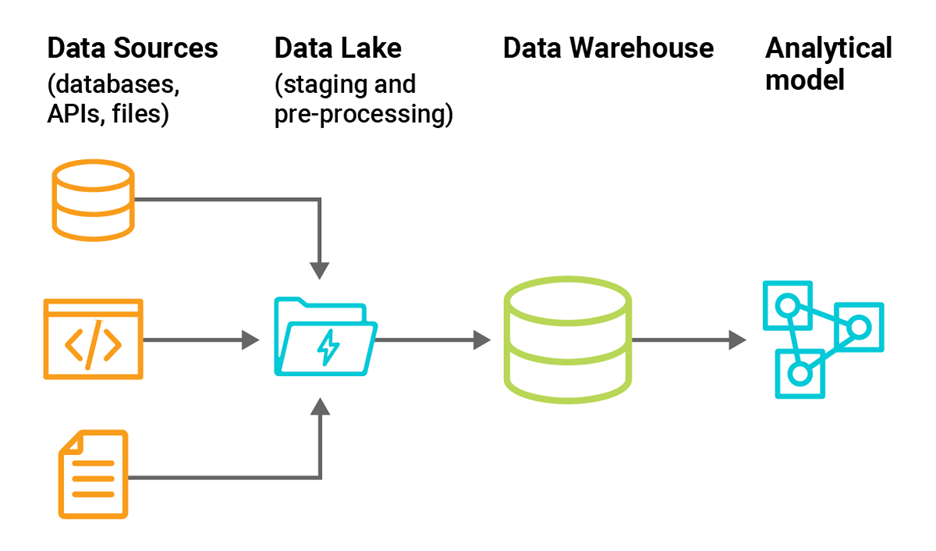
Figure 1: Data flow for a data warehouse that uses a data lake
What About Cloud Data Warehouses?
Many cloud vendors, such as Microsoft and AWS, have a platform-as-a-service (PaaS) data warehouse offering. This removes the requirement to create and manage virtual machines or to maintain an on-premises appliance. With a PaaS solution, the cloud vendor is responsible for servers, storage, networking, operating systems, middleware, and the database management system—including upgrades and patching. This reduces the maintenance overhead associated with a traditional data warehouse, in addition to providing a host of other benefits:
- Fast and easy scaling of resources to accommodate new data loads or data analysis
- Reliable backup and restore of databases
- Built-in high availability
- Ability to rapidly deploy a new environment
Monitoring your Data Warehouse
If you are building your data warehouse using Azure, check out SolarWinds® SQL Sentry. SQL Sentry can help you optimize performance in your Azure SQL database by providing metrics you can use to more easily forecast resource allocation based on utilization, monitor usage, and alert on events happening within the database. If you are building your data warehouse in SQL Server, Database Insights for SQL Server can help you with performance monitoring, index and query tuning, and more with its comprehensive database management features.





