One of the biggest mistakes I’ve had to repeatedly help companies fix has been poor partitioning design. I’ve seen many database architectures designed in an attempt to make queries faster. While faster queries can be a product of implementing partitioning correctly for a given design, I’ve often seen query response times get much slower from implementing partitioning incorrectly for the database design.
Partitioning a table generally requires a single column that is used to determine how the data in the tables will be distributed. To do this correctly, your architecture must be designed in such a way that all query predicates and join statements include the partitioning column. If the partitioning column isn’t included in such a way as to exclude unnecessary partitions from the query, performance will ultimately suffer.
This article will discuss the various partitioning capabilities available in Azure Database for PostgreSQL and provide best practices and insights into how crucial architecture is when it comes to optimizing performance.
What is Partitioning?
Partitioning is the process of taking one, often large, table and splitting it into many smaller tables, usually on a single server. Partitioning has historically been done for administrative reasons—giving you the ability to load or unload data quickly from a table or move less-used data to cheaper storage.
However, partitioning can also speed up query performance. One example of this is partitioning a table by date and having the most accessed records in a single partition. By doing this, the query engine doesn’t have to retrieve records from other partitions, an optimization resulting in faster query execution times.
Partitioning vs. Sharding
Typically, when we think of partitioning, we’re describing the process of breaking a table into smaller, more manageable tables on the same database server. However, in some use cases it can make sense to partition your database tables where parts of the table are distributed on different servers. This is known as distributed horizontal partitioning—and is sometimes referred to as “sharding.”
Implementing database sharding so that portions of the data are on different nodes can be a challenging engineering problem to solve on your own. Successfully implementing a distributed database requires a coordination layer to map data to different nodes. And, your data model must be able to accommodate such a distributed design. Multi-tenant environments where each customer has their own data set tend to work well for distributed databases.
Table Partitioning in PostgreSQL
There are three types of built-in single table partitioning available in PostgreSQL.
Range Partitioning
This option distributes data to different partitions based on a range of values for the partition. Date columns are generally an excellent choice for this type of partitioning.
List Partitioning
This option distributes data to different partitions based on a list of values. Column values in the table matching a given value in the list are placed in the relevant partition. This is a good option if you want to separate different client/customer values into separate partitions.
Hash Partitioning
This option distributes data based on a hash algorithm operating on a column in the table. This is a good option for loading data into a table quickly as it tends to evenly distribute data across partitions. Consider this option when you don’t have a good candidate column to partition the table. A monotonically increasing column tends to be a good choice for the partition column for this flavor of partitioning.
How to Range Partition
Because range partitioning is the most common type of partitioning, I’ll start with an example of how to set this feature up in Postgres. For this demo, I‘ve already provisioned Azure SQL Database for PostgreSQL Flexible Server via the Azure portal.
First, I’ll create a PostgreSQL database named partitiontest.
create database partitiontest;
Next, I’ll create a table named sales. I’ll tell PostgreSQL to range partition this table based on the saledate column (known as the partition key).
create table sales
(
saleid bigint not null,
saledate date not null,
productid bigint not null,
saleprice decimal not null
) partition by range (saledate);
I’ve declared the sales table to be partitioned based on the saledate column, so the next step is to create the associated tables to support the data distribution in the table. There are two ways to accomplish this in PostgreSQL: declarative partitioning and inheritance. PostgreSQL is an object-relational database in which one of the features is one table can inherit base features from another table.
Instead of diving into inheritance for database tables, I’m going to focus on declarative partitioning. With this approach, I’ll create new tables, which are partitions of the sales base table. I’m going to partition this sales table by month, so I’ll need one table for each month I intend to be inserted into the table. For simplicity, I’ll create three different partitions: July, August, and September of 2022.
CREATE TABLE sales072022 PARTITION OF sales
FOR VALUES FROM ('2022-07-01') TO ('2022-08-01');
CREATE TABLE sales082022 PARTITION OF sales
FOR VALUES FROM ('2022-08-01') TO ('2022-09-01');
CREATE TABLE sales092022 PARTITION OF sales
FOR VALUES FROM ('2022-09-01') TO ('2022-10-01');
Next, I’ll add some data to the sales table. Here I’m merely generating some random values to insert into the table. I must be careful only dates between 7/1/2022 and 10/1/2022 are entered into the table. Dates outside this range will result in an error on the insert as partitioning creates constraints behind the scenes to ensure only those ranges specified in creating the partitions are allowed.
insert into sales(saleid, saledate, productid, saleprice)
select
generate_series,
cast (now () as date) – cast (round (generate_series * generate_series)
as int) % cast((cast(now() as date) - cast('2022-7-1' as date)) as
int),
(cast (((random () * random () * generate_series) + generate_series) as
int) % 10) + 1,
cast (((cast (((random () * random () * generate_series)
+ generate_series) as int) % 10) + 1 + generate_series) as decimal)
from generate_series (1, 20000);
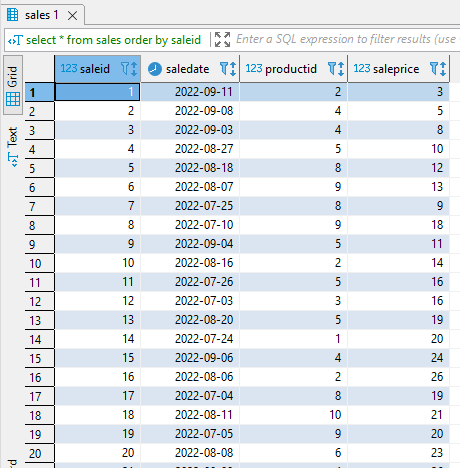
I can query the sales table to see all the records inserted into the table.
select * from sales order by saleid;
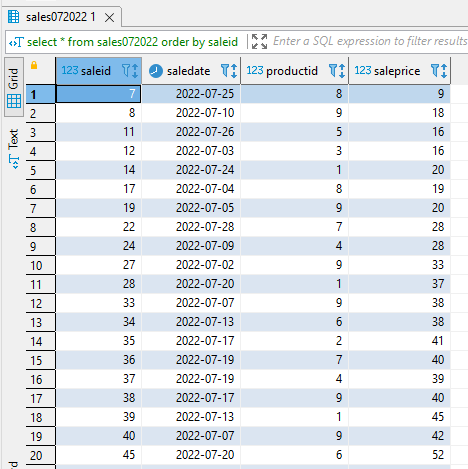
But I can also query each of the partition tables directly to see their values. Here I can see the sales072022 table only contains those rows where the saledate is in July of 2022.
select * from sales072022 order by saleid;
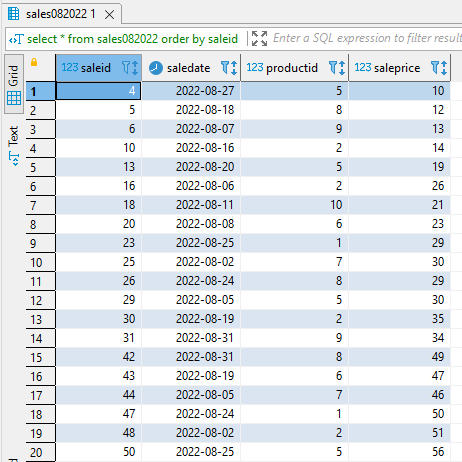
The same goes for those records entered for August 2022—they’re present in the sales082022 table.
select * from sales082022 order by saleid;
Also, notice there’s no overlap between the three partitions of the table. The saleid is unique and monotonically increasing.
select * from sales092022 order by saleid;
PostgreSQL will happily let me know if I try to insert a record having a saledate not falling into the range of any of the partitions I declared earlier:
Sharding With Azure Database for PostgreSQL Hyperscale
As I mentioned earlier in this guide, “sharding” is the process of distributing rows from one or more tables across multiple database instances on different servers. The advantage of such a distributed database design is being able to provide infinite scalability. However, this is a complicated solution to roll out yourself as there must be a well-designed translation layer or a well-known scheme for mapping connections to the correct node. Additionally, you’ll need a sophisticated reporting solution to aggregate data from all the nodes in the database if you want a ‘single pane of glass’ view across your data estate.
While I’ve written about how an group is set up before, let’s review a quick refresher on the main components of the Hyperscale server group.
Coordinator Node
The coordinator node is the entry point into the Hyperscale cluster, as it accepts application connections as well as relaying queries sent from applications to the different worker nodes, which it then takes the results back to the end user.
Worker Nodes
Worker nodes are the nodes in the server group for storing distributed data. The query engine knows how the data is distributed among the different worker nodes and will pull the necessary information from each node to the coordinator node to satisfy the queries being issued. You can scale resources on existing worker nodes as demand increases or add worker nodes as necessary. Through the Azure portal, you can scale out your workload up to 20 nodes—with the possibility of expanding to more nodes if you work with Microsoft directly to do so.
High availability (HA) for Hyperscale happens through a warm-standby node. When enabling HA, the coordinator node and all worker nodes receive a warm standby, and data replication is automatic. As you’re doubling the number of servers involved in the topology, the cost will also double.
Distributed Tables
Distributed tables are horizontally partitioned among the different worker nodes, with each node having a subset of the data in the table. To distribute a table, a distribution column must be chosen when defining the table; values from the distribution column map to different worker nodes. Much care must be taken when defining the distribution column for tables—poorly chosen columns can result in poor colocation of joins, which means a bunch of data movement will need to occur when joins between tables occur, severely limiting workload throughput.
I’ve already gone through the process of building my Azure PostgreSQL Hyperscale server group. In this configuration, I have a single coordinator node and four worker nodes. The goal for this demo is to horizontally partition the sales table in a similar fashion to the demo above for table partitioning. The difference here is the table’s data will be distributed on different worker nodes in the Hyperscale setup. My first step is to create the sales table.
create table sales
(
saleid bigint not null,
saledate date not null,
productid bigint not null,
saleprice decimal not null
);
I must pick a column to distribute this table, known as the shard key. Azure Database for PostgreSQL Hyperscale uses hash distribution, which means a specific value will always deterministically hash to a specific worker node. To evenly distribute my data among the different worker nodes, I’ll use the saleid column because it’s unique. So, I’ll first create an index on this column.
create index idx_sales_saleid on sales (saleid);
Next, I’ll distribute the table via the create_distributed_table PostgreSQL function. This function performs all the heavy-lifting work of horizontally distributing the table data for us behind the scenes.
Now I’ll generate 20K rows to insert into the horizontally distributed sales table.
insert into sales (saleid, saledate, productid, saleprice)
select
generate_series,
cast (now () as date) – cast (round (generate_series*generate_series) as
int) % cast ((cast (now () as date) – cast ('2022-7-1' as date)) as
int),
(cast (((random () * random () * generate_series) + generate_series) as
int) % 10) + 1,
cast ((( cast((( random () * random () * generate_series) +
generate_series) as int) % 10 ) + 1 + generate_series) as decimal)
from generate_series (1, 20000);
Let’s now look at some of the internal Azure Database for PostgreSQL Hyperscale system views. There are far too many system views related to Azure Database for PostgreSQL Hyperscale for me to cover everything, so I’ll focus on a couple of the more interesting ones.
First is the citus_tables metadata system view. This will show all the tables in the citus database and the table taxonomy. We can see from the system view output the sales table is a distributed table with the distribution column of saleid.
SELECT * FROM citus_tables;
To view the number of nodes in my Hyperscale server group, I can query the pg_dist_node system view. Here we see I have four worker nodes and one coordinator node.
SELECT * from pg_dist_node;
Pro Tip: Don’t Implement Sharding Yourself
In this guide, we looked at two built-in options in Azure Database for PostgreSQL for distributing data. By using table partitioning, you can distribute table data into different tables on the same PostgreSQL server. It can be extremely useful for manageability and query performance. Azure Database for PostgreSQL Hyperscale is a sharding solution giving you the ability to infinitely scale your database workload while abstracting much of the complicated aspects of sharding a relational database system. I would highly recommend exploring this offering over designing your own sharded architecture.
It’s incredibly important to understand the challenges you’re going to face if you decide to design your own sharded database. One incorrect design choice and the overall performance of the system can suffer greatly. To more easily stay on top of database health, learn more about SolarWinds PostgreSQL performance tuning solutions here. For help automating and maintaining PostgreSQL documentation, you can also check out SolarWinds Database Mapper.