I was interested in the data shown in PayPal’s blog post on switching from Java to Node.js, for two reasons. First, at a glance both sets of benchmark data looked very clean and fittable to the
Universal Scalability Law to assess where the bottlenecks lie. Second, stepping back and taking a broader view of the blog post and the supporting benchmarks shows immediately that either something is very wrong, or we’re not hearing the whole story.
Modeling With The Universal Scalability Law
I modeled both datasets with the USL quickly, and as expected, got a very good fit (better than 99.9% R-squared) with both. Here’s Java:
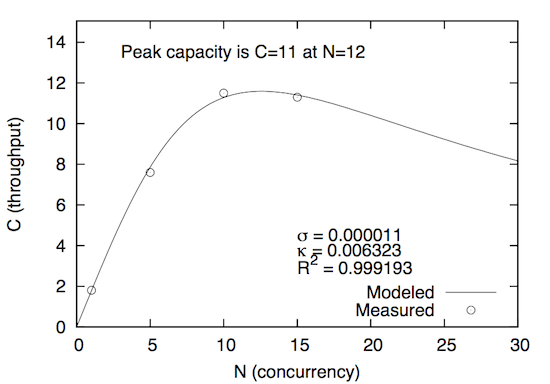
And here’s Node.js:
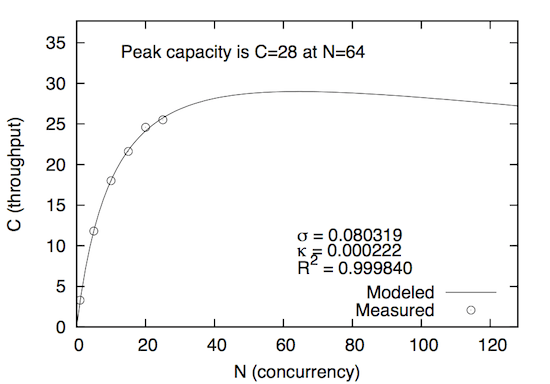
To compare the systems directly, it’s helpful to plot them on a single chart:
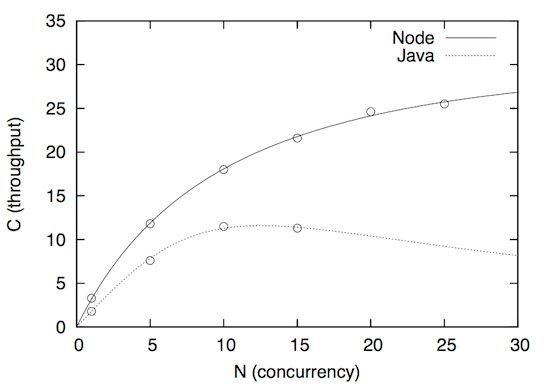
Unsurprisingly, the USL predicts that both systems won’t scale much farther than they’re measured; I could tell that at a glance from the original charts, because they both showed obvious nonlinearity, and in the case of Java, the beginnings of retrograde scalability. But they are exhibiting that nonlinearity for
different reasons, and that affects their scalability functions dramatically. What explains this?
Notice that Java’s sigma (serialization) parameter is lower and its kappa (crosstalk) parameter is higher than Node.js, and the reverse is true for Node.js. This means that Java is bottlenecked less on serialization, and Node.js is bottlenecked less on coherency delays. This is exactly what one should expect from their architectures (multi-threaded versus single-threaded with event loop) and their blog post (“using a single core for the node.js application compared to five cores in Java”). That is the the obvious explanation (though we’re definitely jumping to conclusions if we accept that). This is part of the power of the USL: it tells you which factor is to blame for non-linear scaling.
If you’re not familiar with the Universal Scalability Law, you should read up on it. It provides a model that helps quantify why a system’s performance degrades under higher concurrency (or with more hardware, but that’s a different topic). I wrote several white papers that referenced the USL while I was at Percona. The canonical source is Neil J. Gunther’s book Guerrilla Capacity Planning, but you may find it easier to read secondary sources.
Caveats and qualifiers:
- The USL (and the benchmark) models the entire system as a black box. That is, we’re not just seeing the effects of Node.js versus Java, but the entire application and all of its dependencies and resources.
- We don’t have many measurements for either system, so I wouldn’t be very confident in the results regardless of how good the R-squared seems to be.
What Is Going On With These Benchmarks?
It’s not enough to just take the numbers at face value. Stepping back for a moment, the obvious question is
why aren’t both of these systems performing orders of magnitude better? They’re only achieving low double-digit-per-second throughput for rendering the account overview page! The blog post makes it sound as if the majority of the work is happening in-application (“The application contained three routes and each route made a between two and five API requests, orchestrated the data and rendered the page”).
There’s no way that’s reasonable. If the application is actually doing the heavy lifting here, and there isn’t a lot of latency in those API calls, something is seriously wrong. I suspect that the majority of the latency is in API calls. If that’s the case, it doesn’t make much sense to attribute the performance differences to Java versus Node.js. But if we assume that the API calls are the same for both applications, that makes no sense either.
I have a theory. I happen to know that the JVM is capable of jaw-dropping performance and scalability. (Note that I’m neither a Java nor a Node programmer, and I have no pony in this race.) My guess is that Node is encouraging good programmer practices in terms of scalability, and Java less so. In other words, programmers probably have to work less hard to avoid bad scalability bottlenecks in Node than in Java. Note that the benchmarks measure the performance of a completely rewritten application, with multiple people working for months. I think a lot of engineering effort is being swept into one bucket here and attributed to Node.js alone, and Java alone. I suspect that a lot of the difference should be attributed to a completely different codebase, and maybe different API calls — not just a difference in technology.
Again, though… really? 1.8 pages/sec for a single user in Java, and 3.3 in Node.js? That’s just insanely, absurdly low if that amount of latency is really blamed on the application and the container running it. If the API calls that it depends on aren’t slow, I’d like to see
many hundreds of pages per second, if not thousands or even more. Someone needs to explain this much more thoroughly. The only thing worse than a benchmark is a benchmark that shows an unexplained result.
Conclusions
The takeaway, as I’d state it: PayPal was able to get better results from Node.js than Java. I am not doubting either Java’s or Node’s performance capabilities, or arguing that one system is/ought to be higher performance than another. I’m just saying PayPal’s blog post is glossing over a subject with a lot of unanswered questions, and therefore their assertions about Node.js being better are unqualified and unsupported in my opinion.
We should probably leave it at that.






