First things first: A big shout out to the engineers at Shopify who work on Sarama, the Go Client we use for Kafka - they do a great job on the library!
Alright, now to today’s topic. Compression!
SolarWinds® Database Performance Monitor started using Kafka several months ago to protect against data loss in the event of a problem. For those of you who aren’t familiar with it,
Kafka is a durable message queue that has high throughput and good builtin cluster support to make it resistant to failures. Since deploying it, we’ve saved ourselves a few times from incidents that would otherwise have caused data loss.
The one downside we encountered with Kafka was the disk-usage associated with storing all of the data written to our datacenter. We started with a kafka cluster consisting of 3-kafka nodes (t.2Small EC2 instances, for reference) with a replication factor of 2, then jumped to 5 nodes and a replication factor of 3 almost immediately once we had switched to routing our traffic through kafka. Our storage needs have grown linearly since then, and we have been adding disk space to our nodes. In December, we jumped again to 11-nodes in our cluster (still a replication factor of 3) to spread the amount of data stored-per node and keep from overloading the individual machines.
We looked at compressing messages in Kafka using snappy-compression when we started using it but ran into problems with lost data when we enabled the compressed protocol. We assumed it was a bug with Sarama and shelved the idea since it wasn’t a priority at the time. Around the time we scaled our cluster to 11 nodes, we checked back on the development for Sarama and found they had written a new Kafka Producer for the library. They had also identified the problem we were seeing when we used compression previously - it turned out it was a bug in Kafka (
see here: https://issues.apache.org/jira/browse/KAFKA-1718)! Once we upgraded to the new producer, we were able to turn on compression for our messages which cut their size in half! You can see the effect below on the network traffic from a couple of servers that read and write to our Kafka cluster, respectively.
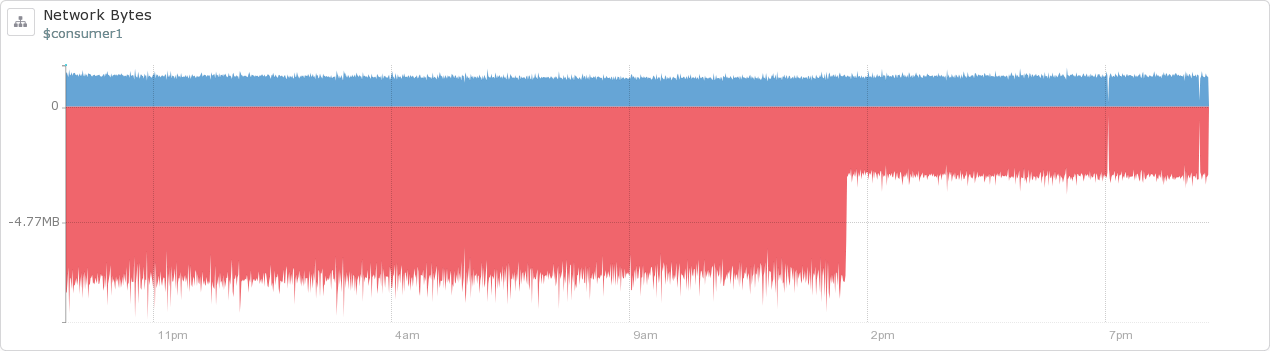
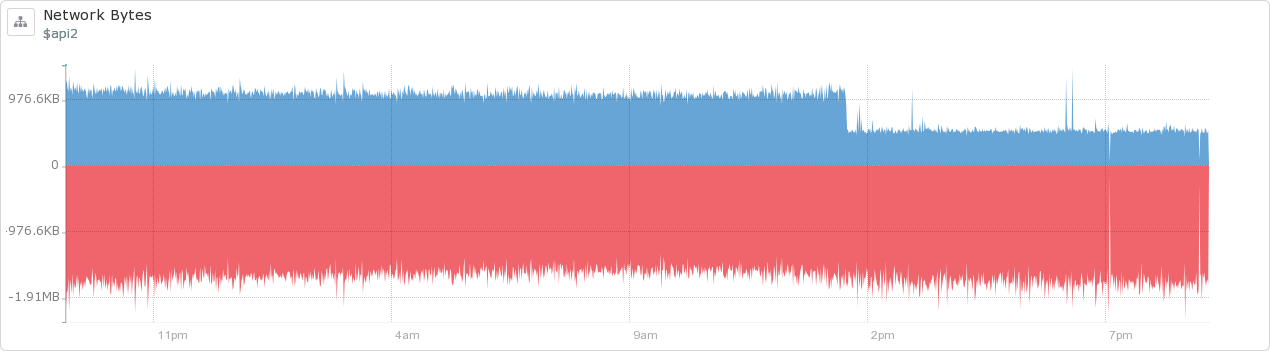
The result for our datacenter is a lot less data going across the network behind the scenes, and the size of the data we keep on disk has been reduced significantly, along with our costs.






