Sampling is hard. This is the title of a talk I gave at a meetup in Boston a few weeks back. But what’s so hard about sampling anyway?
To begin with, let’s clarify what I mean by sampling. It’s a bit ambiguous because sampling could apply to a few different things one does with time series data. In this context, I’ll be talking about capturing individual events from a large, diverse set of events (queries).
Here’s a picture of a simple stream of events over time.
Notice that they are not all the same–some of them are higher or lower than others. This is a simple illustration of some variability in the stream.
The way SolarWinds
® Database Performance Monitor (DPM) generates query insight is by computing metrics about the events. We compute running sums of things like the latency, errors, and the count of queries we see. Once a second we send the sums to our APIs and reset all the counters. That’s how we generate per-second metrics about the events. The metrics are a lot less data than capturing every individual event, so this is a lot more efficient:

The problem is, if we now just discard the original events we lose a lot of information. In the context of a database server, it’s really important to have the original query, with its properties such as the user, latency, origin host, and above all the SQL or other text of the query. We really want to keep some of the queries from the stream.

That’s the goal. The quandary is that this is a lot harder than it seems.
One reason is that we have several requirements for the sampling. We want it to be:
- Representative
- Sample enough queries to be useful, but not so many that it overloads us
- Achieve the desired overall sampling rate
- Sample different kinds of events in a balanced way (e.g. frequent events should not starve the sampling of rare ones)
- Biased towards queries we know are important (e.g. they have errors)
- Allow blacklisting and whitelisting
To understand why these requirements are so important, consider what happens when a query has some kind of behavior that needs to be fixed. It often shows up as a specific type of pattern. Here’s a problematic query from an early version of our
time series backend:
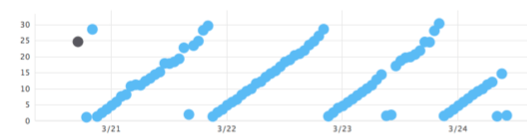
If we didn’t select representative samples of that type of query, that pattern would be hidden.
This is also made much more complicated by the fact that streams of queries to a database server are not simple. They’re extremely rich and varied. This might be a better picture:

Imagine how that picture would look with a million different kinds of queries that all vary in frequency, importance, latency, and so on.
In this context, the goals and requirements conflict in some important ways:
- Rate limiting conflicts with biasing towards important queries
- Rate limits overall conflict with sampling rates of each kind of query
- Rare queries and frequent queries conflict
- Efficiency and correctness are a constant trade off
Our first sampling implementation was a series of equations that kept track of how long it had been since we had selected a sample for each category of queries. As time passed, we became more and more likely to choose each query we saw, until we chose one and reset the probabilities again.
It sounds good, but it didn’t work. Some queries were
way oversampled, and others never got sampled, and we got enormous numbers of samples from some customers and not many from others.
The user experience is the most important thing to keep in mind here. When a user looks into a query’s details, they should be able to look at a reasonable time range and get a reasonable number of samples to examine, EXPLAIN, and so on.
Our naive approach wasn’t the only one. From past experience I had seen a variety of ways to do this. The easiest way (and the one I built into pt-query-digest by default) is to select the “worst” sample you see. But that’s not representative at all. You’ll end up with nothing but the outliers, and a lot of queries have multi-modal distributions, so you’d never see a lot of the most representative samples.
Selecting every Nth event is another simple approach, but it creates disparities between rare and frequent queries.
The ideal approach is to sample a random event per time period per type of query, but our implementation wasn’t working as we wanted it to.
The solution turned out to be an interesting combination of math, statistics, and approximate streaming algorithms (a sketch). I’ll write about that in a followup blog post, since this one is getting kind of long already.
If you’re interested in this topic, Preetam and I presented on it at
Monitorama, and the video is online.






