
How Does a Distributed System Work?
Distributed systems don’t have a single design or implementation pattern—instead, they break down into patterns aligned with various types of business problems. An example of this is the sharded pattern for stateful services like databases. This allows you to horizontally scale your data tier to avoid performance bottlenecks and single points of failure. This pattern is illustrated in Figure 1 below and is commonly referred to as a distributed database.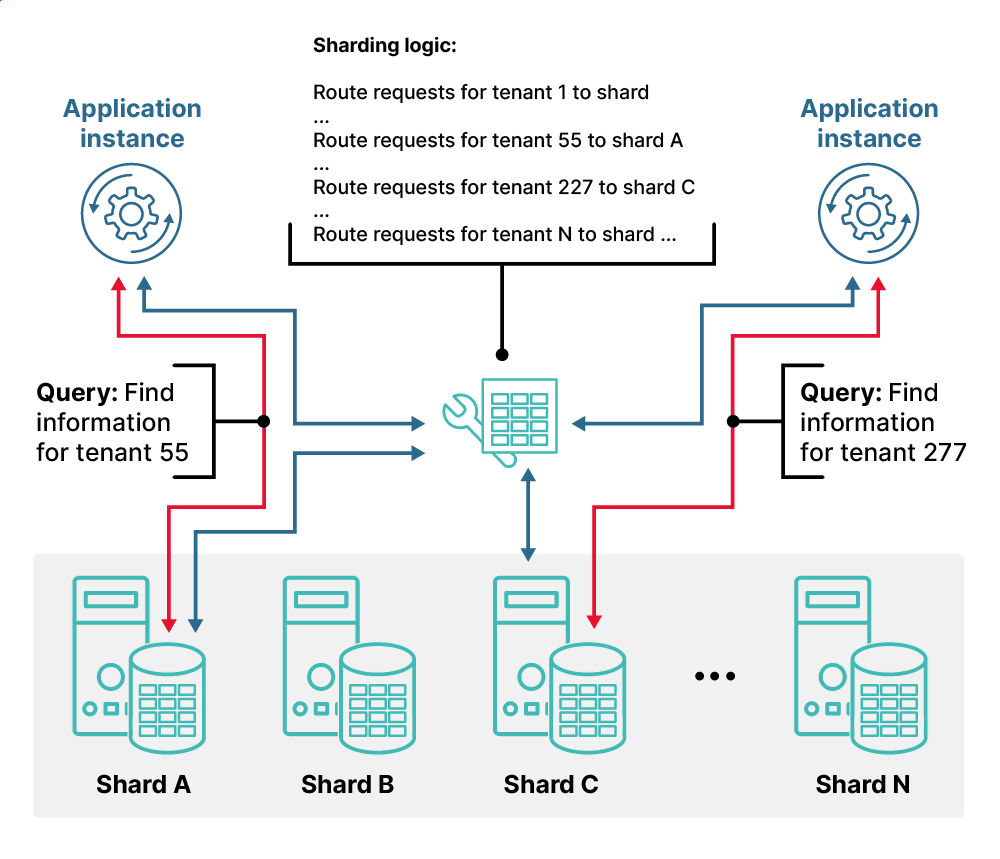
Figure 1: This image illustrates the sharded pattern of a distributed system.
The other element of how distributed systems work includes how all the elements communicate with each other using REST (Representational State Transfer) APIs, a set of definitions and protocols which allow two systems to communicate with one another. These APIs often serve as an abstraction layer to the direct language needed to access the target system. This allows for easier and faster development. It’s important to understand the latency between these systems, even within a single compute environment, because it will have a direct effect on the overall performance of the distributed computing system.Key Concepts and Architectural Design Elements of Distributed Systems
Early distributed systems were built from the ground up in a custom manner. This led to overly complex systems—however, a few paradigms changed to make distributed architecture easier to deploy. The first is the broad adoption of virtualization, but not just virtual machines. The concept of virtual networking allows for key distributed systems concepts like software load balancing, which allow for stateless workloads to easily scale horizontally. The other changes are the ubiquity of cloud computing from vendors like Amazon and Microsoft, which allows nearly any component to be software-defined. It also enables container orchestration platforms like Kubernetes, which also allow for “infrastructure as code” and provides service resiliency in the event of hardware failure. You may notice a general trend of abstractions here—whether it’s software-defined networking or a SQL tier behind a REST API. Using these abstractions allows for faster development cycles and added flexibility. You can easily add complex networking rules in your code without ever having to log in to a router, or you can design a web tier to scale to more instances based on the average CPU utilization or memory consumption. These design patterns are helped by containers, which themselves are an abstraction of a host operating system at the application layer, whose lightweight design allows for easy deployment. Adding a new VM to a load balanced set can take minutes, while adding an additional container to a Kubernetes replica scale set pod can happen in a matter of seconds. Beyond these design patterns, a key concept of distributed systems is desired state configuration and service healing. For example, in Kubernetes, the head nodes will keep all the defined objects in the cluster—if for example, a database pod is suddenly unavailable or missing, because of service healing, the cluster will redeploy those pods. While this example is specific to Kubernetes, these concepts apply to many distributed systems to cut single points of failure.Types and Examples of Distributed Systems
Distributed computing systems support most of the modern web and blockchain systems; however, let’s look at some specific examples of systems, which have largely replaced traditional client-server systems. One common element of a distributed system is a microservice architecture, where each computing function is broken out into its own service. An example of this is shown in Figure 2 below.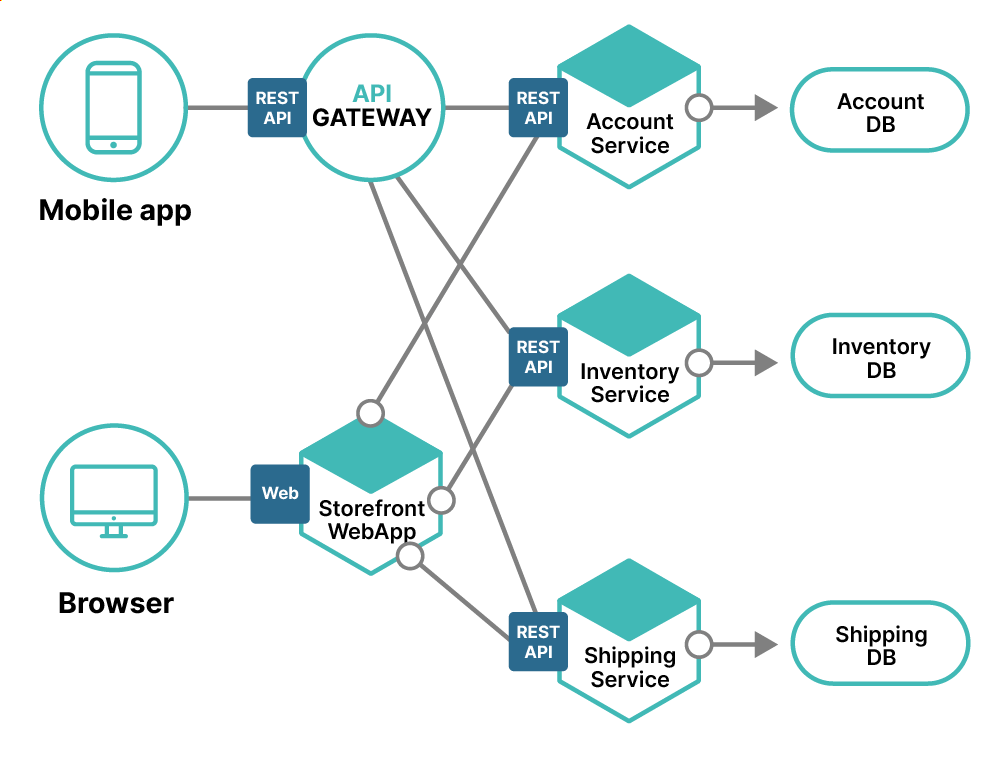
Figure 2: This diagram shows the microservice architecture of an e-commerce application.
This example is a simple e-commerce application designed to process orders from customers via both mobile apps or web browsers and then handles the order fulfillment process through a series of related APIs, including a database for each function. The benefit to this pattern is any of these components can be easily swapped out for a different technology without affecting the overall system.




