MySQL is the most used database in the world. And as it continues to grow in popularity as an open-source database system for developers, understanding how these indexes work is an important step for database developers and administrators.
This tutorial is going to explore clustered indexes and secondary indexes in MySQL. MySQL also has other types of indexes besides the B-tree indexes I’ll be discussing, such as fulltext indexes and hash indexes. However, I’m going to omit those indexes for this article as they are somewhat specialty indexes suited for text-based searches and speedy single-record lookups.
For database professionals, implementing the correct indexes for the workload is the foundation of any well-running relational database system. Adding and adjusting indexes to suit the workload has yielded some of the most significant performance gains over my many years of consulting. However, to add the right indexes, you must first understand the common types of indexes in MySQL, how to create your own indexes, and I’ll also provide more insight into the database performance advantages of properly using them.
Clustered Indexes
Clustered indexes are data structures that store the data of database tables. It’s important to understand that the clustered index
IS the table, and all MySQL tables have a clustered index, which orders the rows in the table based on the clustered key. In MySQL, clustered indexes and secondary indexes are both B-tree data structures. The B-tree index is a commonly used database index structure in the relational database world because it allows for rapid searching and sorting of data with minimal storage overhead for the index. To accomplish both tasks, the B-tree index must maintain the data in the structure in sorted order.
When a table has a primary key or unique constraint, MySQL will cluster the table based on that primary key or unique constraint. These tend to be good candidates for the clustered index key as they are highly unique. However, when a table is created without a primary key or unique constraint, a clustered index is still generated behind the scenes for you. More on this later.
How to Create a Clustered Index in MySQL
First, let’s create a test database for these demo examples. For the Graphical User Interface (GUI), I’ll use
DBeaver Community Edition – an excellent interface for developing and administering various database instances. For the MySQL database, I’ll be using
Azure Database for MySQL Flexible Server. Azure makes it very easy to spin up a MySQL database server, so I can run my demos and then tear down the instance quickly, with minimal costs incurred.
MySQL is unique in that it has the option to use different storage engines. Different storage engines can provide varying levels of functionality. The storage engine I will be focusing on is the InnoDB storage engine, as it is the most used engine for relational database purposes.
My first step is to create a test database for our demos:
create database sqlskills;
I’ll then switch to my sqlskills database context via the use command:
use sqlskills;
Next, I’ll create a table named numbers with two columns; numbercol, which will store monotonically increasing values, and charcol, which will store a randomized string, with data types int and varchar respectively:
create table numbers
(
numbercol int not null,
charcol varchar(100) not null
);
Here I will query two different
information_schema tables for the InnoDB storage engine. The innodb_indexes view stores information regarding indexes, and the innodb_tables view returns information regarding tables. We see from the output that there is an index with the name of GEN_CLUST_INDEX, which was created automatically for us when the table was created.
select
ii.index_id,
ii.name,
ii.table_id,
t.name
from information_schema.innodb_indexes ii
join information_schema.innodb_tables t on ii.table_id = t.table_id
where t.name = 'sqlskills/numbers';
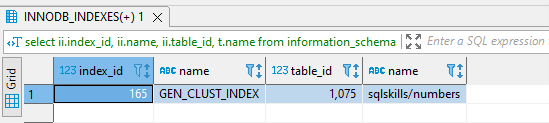
As I mentioned before, when there is no primary key or unique constraint on the table, InnoDB generates a hidden clustered index named GEN_CLUST_INDEX on a 6-byte synthetic column which contains monotonically increasing row ID values. These values are ordered by the row ID physically in order of insertion.
I’ll use a recursive SQL common-table-expression (CTE) to generate a list of 5,000 numbers and random string values to insert into the numbers table. Notice I use this random number in the
ORDER BY statement to insert the data into the table randomly.
set session cte_max_recursion_depth = 5000;
insert into numbers(numbercol, charcol)
with recursive cte (n) AS
(
select 1
union all
select n + 1 from cte where n < 5000
)
select n, left (md5 (rand ()), 100)
from cte
order by 2;
Now when I run a SELECT against the table, the data is returned in a random order:
select * from numbers n;
I can use the
EXPLAIN keyword to return the execution plan for a query. When it is used with the ANALYZE option, the query's actual execution plan is returned. In other words, the query is executed, and the query execution plan is surfaced. We can see from the output of the execution plan that the number of rows touched is 5,000 – or the entire number of rows in the table, along with a high cost. In other words, even though this table does have a Clustered Index, it is not useful for querying purposes because the index key is essentially the rowid – which doesn’t include the numbercol column.
explain analyze
select * from numbers n
where numbercol = 1000;

To create a clustered index on the table on the numbercol column, I can add a primary key constraint to the table. This column does not contain null values; each row value is unique, so it is a quality candidate for the primary key constraint.
alter table numbers
add primary key (numbercol);
When I run the same query as before, along with the actual execution plan, we see the number of rows touched is only one this time – a very significant performance improvement.
explain analyze
select * from numbers n
where numbercol = 1000;

B-tree indexes can be considered an upside-down tree structure where the root page is at the top. Intermediate-level pages store pointers to additional pages in lower levels in the index. For MySQL clustered indexes, once you get to the leaf level of the index – all the columns in the table are stored in the B-tree structure. These intermediate level pages and leaf level pages are doubly-linked lists – they maintain the ordering of the index, so it is possible to easily find values in the ordered list but also to be able to order the resultset in ascending or descending order without additional work to provide the sort. There is no separate storage for table data.
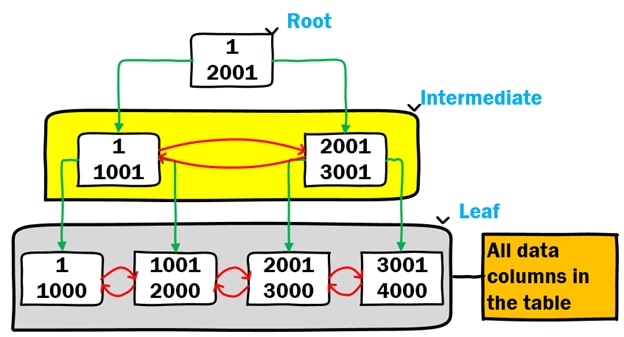
Secondary Indexes
Any index on a MySQL table not within the clustered index is known as a secondary index. Secondary indexes are also B-tree indexes and essentially operate similarly to the clustered index – they’re stored and maintained in sorted order.
Consider the following high-level diagram of a MySQL secondary index. The design is almost the same as the clustered index – with the only difference being what is stored at the leaf level of the index.
While the leaf level of the clustered index stores all the column values for the row, the secondary index leaf level only stores the columns defined in the index (with the left-most key being the column that orders the data structure) and some pointer back to the base table. It is also worth noting that pages at the leaf level are also doubly-linked lists, supporting previous and next page lookups as well as bi-directional sorting.
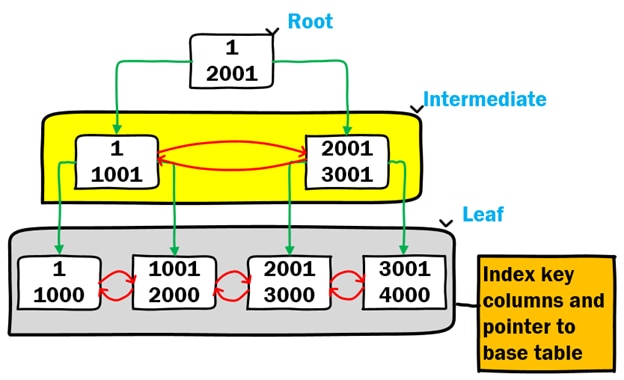
How to Create a Secondary Index in MySQL + Example
Let’s look at an example of where a secondary index can speed up query performance. Here I have pulled one of the random values from my numbers table to use in the where clause. You’ll need to do the same as you likely won’t have the same random text values in your charcol column as I have in my table. Notice in the execution plan a table scan was performed, and all the rows in the table were examined to find this single row. This is not an efficient operation and an excellent opportunity to add an index.
explain analyze select charcol from numbers n
where charcol = 'b331b0fe3e800bd8fb0fd0786c5a2067';

Now I’ll create a secondary index on the charcol column. The syntax here is simple: create index index_name on table_name (column_name).
create index idx_numbers_charcol on numbers (charcoal);
When I run the same query again and grab the execution plan, I can see a dramatic difference in performance. This time there is a covering index (covering means it covered all the necessary columns returned in the SELECT statement) that the query optimizer can use, and only a single row was touched. This is an ideal case for creating a secondary index to improve query performance!
explain analyze select charcol from numbers n
where charcol = 'b331b0fe3e800bd8fb0fd0786c5a2067';

Clustered Index vs. Secondary Index
There are three significant differences between the two types of MySQL indexes you should know:
- Because the clustered index IS the table, you can only have one of them. You can have multiple secondary indexes per table in MySQL, and this is encouraged to create indexes specific to your querying needs.
- Secondary indexes generally only contain a subset of the columns in the table. These indexes are meant to speed up searches for data and to help sort data, so it’s generally not advisable to include all the columns in the table in the secondary index. It would be a waste of space and memory to do so.
- There is a relationship between the clustered index key and the key of the secondary indexes. Because secondary indexes are copies of data in the base clustered table, there must be a way to associate the record in the secondary index to the full row in the clustered index. To facilitate this, for each row in the secondary index, the clustered key for that row is also stored. This is important to understand because the wider the clustered index key is for your underlying table, the wider your secondary indexes will be.
Pro Tip: B-tree Indexes FTW!
B-tree indexes are generally the index of choice for most InnoDB implementations in MySQL because they allow for the quick searching and sorting of data, have little overhead, and are great with inequality lookups. Understanding when and how to implement these indexes is one of the best tools in the toolbelt of a database professional.
From MariaDB and Percona servers to cloud and VM deployments, SolarWinds has database performance management solutions built to support a range of MySQL instances. Learn more about our
MySQL Solutions.






