
- If you create a plethora of alerts to which IT staff must respond, they’ll end up spending the bulk of their time on them. This may make IT operations less productive and more expensive instead of boosting IT productivity and promoting savings.
- If IT staff must deal with mountains of alerts, how will they know which ones are important and which ones can be handled later? Again, lack of priority or urgency may make IT less effective and efficient and more costly.
Choosing and Using Alerts Wisely
Rather than pursuing a “more is better” strategy when creating alerts, IT organizations should focus instead on a “small is beautiful” system and application alerting strategy. Numerous other considerations and characteristics are important to consider and address when creating management alerts as well. These include the following:- Accurate classification and prioritization. Anything threatening the organization’s ability to conduct business, collect money, or keep customers happy needs immediate attention. Other conditions or events—such as resource usage thresholds or slow response times—must be addressed, but probably not right away. IT staff needs guidance on what’s important and the order in which they should tackle pending alerts. From a cost management perspective, putting out expensive fires and limiting losses (both actual and potential) must drive alert scheduling and assignment.
- Remediation guidance and help. Where automation can cover and resolve alerts, it should do so. In such cases, IT staff need not get involved unless automated resolution fails. Where automation can’t handle an alert entirely on its own, if it can provide guidance based on prior history, known remediation or workaround techniques, or useful resolution strategies, it should provide this information to give IT staff a jump-start and make sure they’re heading in the right direction. In most studies of IT effectiveness and cost control, automation appears as the number one cause for improved efficiency, responsiveness, and—consequently—cost savings.
- Wherever possible, the management system should automate alert checks as part of the alerting process. Prior to issuing alerts of any kind—especially those requiring human involvement or intervention—it should eliminate as many false positives as possible from the pending alert queue. In general, anything capable of reducing the number of alerts without compromising performance, integrity, or security or adversely affecting key performance indicators (KPIs) is a good thing. Here, again, it’s a matter of separating signal from noise so IT teams can stop wasting time (and money) on low-priority or unnecessary responses.
- Using a well-informed baseline to drive alerts is key. What may provoke an alert in one situation may be entirely normal in another situation. For example, frequent and repeated use of administrative privileges to make and move copies of applications and data sets is normal during a system migration. Under any other circumstances, it should set red flags ablaze. In such a case, it might be wise to temporarily suspend these security alerts while migration is underway. Likewise, resource consumption and usage thresholds may need to be reset during peak or end-of-cycle seasons to account for higher levels of activity and use. By taking account of current and expected conditions, IT teams can focus their efforts where they’ll do the most good. Ultimately, this delivers better services at a lower overall cost.
Example 1: Exceeding a Meaningless Threshold
In keeping with standard policy, an alert comes up showing one server disk is 90% full. An IT staffer is assigned, logs in, checks the disk space, and manages to recover a mere 2MB after 30 minutes of investigation and cleanup. She then determines this disk always runs at 90% capacity, and it’s normal and acceptable to stay this way. She closes the incident and moves on to her next assignment. Alas, this simply means the same incident gets generated and elicits the same response next month, and the month after, and… lather, rinse, and repeat forever. The right response here, after clearing the incident, is to file a change request to inform management staff the threshold for this disk is set too low. An investigation to determine a new and higher threshold value that will actually prompt a meaningful response—such as 95% or 99%—might make a useful change. On the other hand, a request for a bigger disk might also be warranted. In general, anything IT can do to reduce the number of spurious alerts will help staffers focus on more important alerts, thereby improving efficiency and saving on overall IT costs.Example 2: Lost in Alert Overload
Imagine a situation where an organization has created dozens of alerts for its IT staff to handle. These alerts are poorly prioritized and lack sufficient context for IT staffers to separate hair-on-fire situations from smoldering embers. Without a clear sense of which alerts are most dire, IT staffers end up wasting too much time fixing things that don’t adversely affect the business. Worse, these same IT staffers sometimes overlook or don’t get around to resolving tickets costing the organization time, money, and customers because of their inability to place, track, or deliver orders. A proper IT operations management (ITOM) environment includes context with alerts so IT staff can understand the conditions, events, or issues reported within the bigger picture of what’s expected within the organization’s systems. This helps to make sense of how the alert diverges from the norm and what it could portend. Likewise, it’s essential to impose a classification scheme on alerts to help with their priority (e.g., critical, severe, routine, informational) so prioritization and focus naturally fall where they’re most needed. Figure 1 shows a common classification scheme used for fire danger alerts.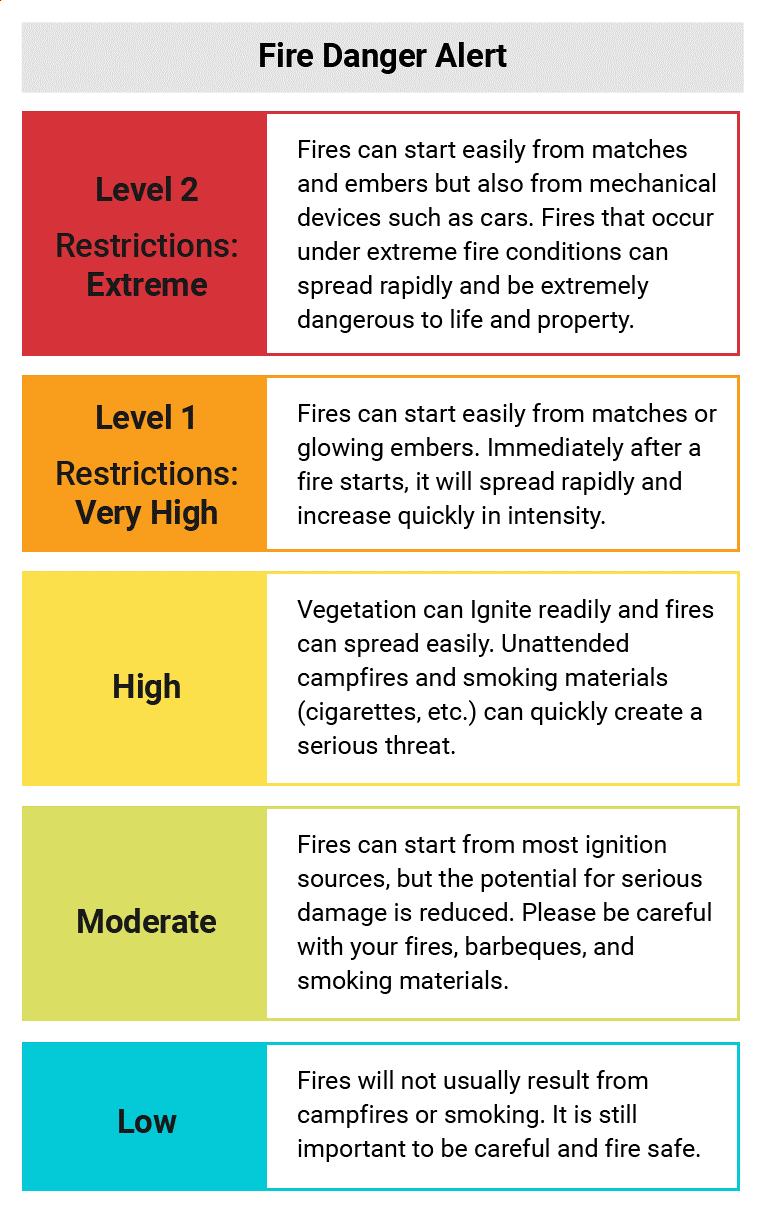
Figure 1: The level of intensity and potential danger goes up as levels of observed fire danger increase. It’s a good model for IT alerts, too.
This is an area where data mining, anomaly detection, and metric correlation are all helpful in keeping pending alerts in order of priority. These technologies use artificial intelligence/machine learning to provide added insight, benefit from prior history and current observations, and help organizations put their efforts into closing tickets capable of providing the most positive outcomes. Because some alerts truly threaten business losses or reputational damage, they must take priority over those posing lower risks. This makes constant, ongoing alert classification and prioritization a vital aspect in any good ITOM environment. Ultimately, this also lowers the overall cost of providing IT services and support, where saved time pays a double benefit in enabling staff to work on things capable of improving productivity, profitability, and efficiency.




