Data, and database growth, is exponential. With this added growth comes added complexity, making it difficult to find resolutions when problems arise. And if this wasn’t difficult enough, the hybrid world in which we live makes performance monitoring and tuning harder than ever. It’s hard to find a single solution that fits all your database needs—from cross-platform support, deep-dive diagnostics, root-cause analysis, and cloud-native focus.
In this episode of SolarWinds Lab™, Head Geeks™ Kevin Kline and Thomas LaRock will show you the basics of database monitoring using free features within Microsoft® SQL Server® like Extended Events and SQL Agent Monitoring. Then they’ll show you how to extend and amplify your database performance monitoring effectiveness with SolarWinds products Server & Application Monitor, Database Performance Analyzer, SQL Sentry, Database Performance Monitor, and Database Insights for SQL Server.
Episode Transcript
– [electronic music]
>>Hi there. Welcome to SolarWinds Lab. My name is Thomas LaRock, Head Geek here at SolarWinds. And along with me is fellow Head Geek, Kevin Kline. Say hello, Kevin.
>>Hi Tom. And hi everyone. Thanks for coming.
>>Yes. We always try to remind people and thank them that we know they have their choice of programming materials during this pandemic. And thank you so much for choosing to spend the time with us today. So Kevin we’re here, we’re going to talk about database performance monitoring, right? There’s more than one way to get the job done. I wanted to know if we could maybe talk a little bit about say the journey of somebody responsible for a database. So I’m just going to ask you, do you remember what it was like for you, say DBA on day zero?
>>Oh my gosh, yeah. What a day to have imposter syndrome, right? In my case, I was actually a really good SQL developer. And when we didn’t have enough DBA resources, the team leads came and said, hey, we need a DBA. You ready to step into that role? And I said, yes. But a little bit of me was not quite ready for that too. So yeah, I remember those days. I remember them well.
>>Yeah. And at the time though, without saying just how experienced you are, let’s just say at that time in history, the level, the maturity of database tools on the market, wasn’t really there. So we all started in the same place, myself included, where we have to use a lot of scripts in order to get diagnostic information out, in order to look at the query plan, things of that nature. Is that probably similar for you as well?
>>Very true. Very true. Now I did have one advantage compared to the average person stepping into the role of a DBA without having a mentor, which is I had spent my previous several years working for the Department of Defense, and before that for NASA, and one of the things that the government had developed at that time in cooperation with Carnegie Mellon University and their software engineering institute, they developed something called the capabilities maturity model for software development teams. And they had another maturity model for, it wasn’t specifically named for DBAs, it was called the information management maturity model but it was basically for DBAs, or maybe if you were again, dating myself, a Lotus Notes administrator, you know one of those kinds of things? [chuckles] But it was wonderful in that it gave you a step-by-step progression to how you could go from being that junior who doesn’t know where to start, to having really really strong control over your organization. And the first step off of being in that chaotic situation, where you’re just responding to fires constantly, and you’re never able to get ahead of the game, that first step was you have to implement some kind of monitoring. If you’re relying on your phone ringing to tell you that there’s a problem, you’re never going to get better. And so that was my first lesson. And so, yeah, I had the scripts. Now I have to take that the next step and see what I can do to stay on top of this. And maybe I can learn about what’s happening before my end users do, fix them before they ever learn about the problem, and life gets a lot better.
>>Now I know that your background, I think you started more Oracle
>>Yes.
>>before SQL Server was even a thing, before even Ashton Tate.
>>Yeah right.
>>But for me, I actually cut my teeth Sybase and some Oracle before I start getting into SQL Server with SQL Server 2000 really. At that time there wasn’t really a lot of options for rolling your own solution when it came to monitoring SQL Server 2000, and with 2005 we got a little more advanced with some dynamic management objects, and extended events came around, so you had to really build your own solution using a lot of queries, and maybe even SQL agent alerts, but this was really all we had. Do you remember those days?
>>Yeah, just like you say, that was the first and really the only thing we could do to build in monitoring at that time, was to to create these SQL agent alerts, and broadly speaking we would put alerts at severity levels. 16 to 18 would be my starting point, depending on the kind of server, all the way up to the maximum severity level in SQL Server, which is level 25. And let it notify us, although its capabilities were very limited. It could send you an email, it could send you a page, in case you were carrying your pager around, right? Or it could do a net send. They have not updated it since then, right? Those are still options in there. [laughing] Or you could also cause it to invoke a SQL agent job of some kind. So maybe you might use that old command SPwho or SPwho2 to see who’s doing stuff on your SQL Server. Or you might say, okay I always get this locking problem, so I’ll have it run a job that is basically the SP log stored procedure. And that was about the extent of it. But just being able to be notified before my end users knew of a problem, that put me ahead of the game.
>>So even with all these scripts, what I found was that if I rolled my own solution, and it might work, but you would hit a certain point where one of two things would happen. Your ability, your custom in-house solution and its ability to scale exponentially as your environment grows, it may not be good for that, right? The code that you’ve written may not scale very well, but more importantly, even as the workload or the number of say, entities, you have to manage grows, you might spend more time being the administer of the in-house application you’ve built, as opposed to administering the database servers themselves. So you get this point where you’ve built something and now you realize now it’s time for me to buy. Was that a familiar or similar for you as well?
>>Well, it was. And I’ll tell you, the real turning point for me, like you mentioned, there were two for me. First was trying to scale up. And once we went from, oh, I dunno 30 or 40 servers to the next step up, that’s when it started to get really hard. We didn’t have scripting languages back then like PowerShell, so we had to do it all in T-SQL, and you had to enable XP command shell, which is a major security issue to run batch files and things like that. The other big hurdle that was so significant at that time was maintenance, right? So, hey, we’ve got SQL agent, this is great, let’s write some code to keep an eye on our SQL Server 2000s. But then when we go to SQL Server 2005, we’ve got all these DMVs now that didn’t exist in SQL 2000, and then we have 2008 come out and things that, so maintaining the system, like you said, and of course the enterprise didn’t automatically upgrade every SQL 2000 or 2005 or 2008 as soon as the new version came out. So that meant we had to write multiple versions of the same code, and that became backbreaking labor. And so just as you said, this was the time at which we said, okay, we gotta buy something. And in fact, it was inspiration for me to change careers from being an enterprise DBA type to being a toolmaker for enterprise DBAs.
>>And, and we’re all the better for you making those decisions. And it brought you here today with me. So we spent a lot of time walking down memory lane. I think the point that we really wanted to do with this conversation was to walk people through that journey. That evolution you have. You become this accidental DBA, you’re running a few scripts, you’re looking at execution plans. You realize you need to have some sort of monitoring and collection happening on an ongoing basis. And then at some point you say, I can’t do this anymore. I need to buy myself a tool, and let the tool do the work for me, so that way I can just use my brain, and analyze what the tool is showing me. And I think for a lot of people, they end up with I just need a high-level solution that’s gonna give me some insight into what’s happening in my environment. And that’s what I’m going to show people right now with SAM and how that works with specifically AppInsight for SQL Server.
>>Yeah. Excellent. And I would even point out that there’s two big aspects to our careers as database professionals. One is that aspect of being the guardian of the data. We got to make sure that the servers are up and running. Our end users can get to the databases. They have the right permissions, or lack the correct permission so that they can’t see stuff they shouldn’t. But then there’s that other aspect that a lot of first timers as DBAs overlook, which is the thing that’s really great about a good database administrator is when they can add value to the business. Right? So I think of things like backups and keeping an eye on alerts, and making sure you keep your servers up and running. I think of that as like, just the day in and day out duties of a DBA, but the really good DBAs are the ones who get invited to the development sessions for the next new application. Right? And so you can provide insight to say, oh you know what? You’re thinking about using these data types because that’s what you learned in your Java classes, or what have you, whatever class you learned from, but that doesn’t actually work really well on SQL Server. We need to stay away from max data types or the old text or image data types. That adds value, that makes the organization more capable. And so when you’re able to say, hey I don’t have to spend all my time fighting fires. I can actually help the dev teams do a better job. That’s when you become a truly valued DBA as opposed to someone who they might say, well let’s just hire a contractor, some sort of decision like that. So adding value to what your IT organization does is where your career really begins to differentiate. But you gotta have good tools that take away that tyranny of the urgent or else that’s all you’ll have time to do.
>>Ooh, I like that tyranny of the urgent. That’s good. We’re going to use that, that should go on a t-shirt. So fortunately for us, we have a handful of tools that can help somebody add that value. And that’s what we’re going to walk through here today. So let’s get started. Let’s take a look at SAM. OK. So I am at the main page for SAM, and you can get there, basically, in your Orion install, if you have SAM you’ll find it in the application dashboard in SAM summary, right? So what this is, SAM does is it’s going to give you that high-level overview that is most likely gonna be good enough for a lot of say the accidental DBAs out there. So server and application summary, and one of the things that it will do for us, it’ll identify that SQL Server is running on a particular monitored node. And then we have this thing that’s gonna be called AppInsight for SQL, which is essentially a template of sorts that we apply and try to highlight the important SQL Server metrics that we are collecting. So of course, being a monitoring company, we have lots of monitoring tools. And for example, we can correlate a lot of additional information. So for example, you can see here that I have cluster information, including network details of how things are connected, right? That’s a right here front and center for you. But if I scroll down, I’ll get information about particular components by say, statistic data, information about alerts, here’s CPU load by different instances. So on and so forth. There’s a lot of information here. Now, Kevin, if you had to build something like this for yourself, back in the day, like how much effort would that have taken you?
>>Oh my gosh, hundreds of hours. Hundreds and hundreds of hours. And then on top of that, it wouldn’t be a single pane of glass. It would be a series of reports that I could flip through. Each one is different query. And then I’d have to pull up a different report for SQL agent failures, and then a different report for event alerts. So this is wonderful.
>>So another aspect though, right? So like I mentioned, we have a lot of correlated data here. We’re collecting a lot of information. Another aspect of this is how it just all works, right? So if your SolarWinds administrator is simply monitors a node and it has a database server installed and running on it, that just gets collected automatically. There’s no additional overhead for you as the administrator to go and enable or add this in. And it just all works. And to me, that’s one of the beautiful parts of this. And here’s another example of something that just works. If I expand this node, then we look at this particular NOCSQL1 I get some information here. I can see it’s red, or at least I can see it’s red, right? I mean, I see the exclamation points. I see that maybe that there’s, I see the words application, that’s critical. So I’m just going to click on this particular instance. And now what you see is what we call the AppInsight for SQL, which is really a template. Now look at the details we have here. I mentioned the connection information. So Kevin, here’s a question. This SQL Server itself, that database engine, does it have any knowledge of network?
>>Not really. But there’s some very broad buckets, like you can tell how much time you spend waiting on the network. That’s about it. [Thomas] – That’s about it. And sometimes you’re not waiting on network, you’re still on the same box, but it shows as a network wait, ’cause you’ve left the engine and SQL doesn’t know what’s happening. But look at this application connection information. I already have details here about this other server connecting to this particular instance and it’s taking 154 milliseconds, which maybe could be an issue, right? That level of detail exists in there. Again, we’ve correlated this with some other products and we’re collecting this information, but this is incredibly valuable. Again, I didn’t have to script this out. Imagine how long it would’ve taken us to try to do this. And again, details that’s gonna be bubbled up, look information on all databases, the size of the database. That’s important at times. Active alerts. How about the environment? Again, we’ve tied everything together for you. And so here you can quickly see that maybe if the issue is down in the storage array, you’re probably not going to spend a lot of time looking at an execution plan trying to tune a query that somebody says is running slow if you already know that the issue is with the array, right? So I mean, how many times Kevin in your life did the phone ring, they told you what the problem that you need to solve, you tried to start solving it, you never solved it, the phone rang again and they said, hey, thanks for all your help. Everything’s great now?
>>It happened probably 65, 70% of the time. I always called that the blame game, because I’d say to myself, oh, okay DBA team, we’re going to have to prove that we’re not to blame for this. So this is a fantastic cohesive approach to everything related, not just to SQL Server, but to servicing the end user.
>>Absolutely. And more metrics for your consumption. And this is all customizable. What’s happening with buffer manager, those counters and cache and memory, latches and locks. And again, colors and bands to identify where something might be abnormal or something to look into. And we can just go on and on and on. I mentioned it’s high level, it’s not just necessarily high level, because it’s giving me information, but it’s really, it’s really just reporting back the raw metrics. The person reading this has to have an understanding of the database itself and know what actions to take next. And that’s what we’re going to talk about next here is sometimes you need a tool that’s going to not just report that something is wrong, but it’s going to help you figure out how to take action to fix what is wrong. And that tool of course is called Database Performance Analyzer. Why don’t we hop over there and let me show you how that works. So Kevin, SAM is great at giving me that high-level say enterprise view of my database servers because that template AppInsight for SQL, it’s specific for SQL Server, but we can show you other database servers as well. we’ll let you know that Oracle is running or a MySQL might be running somewhere. We can customize that to get all those types of details that you might want for that particular application. I mean, that’s the name: Server & Application Monitor. But as I mentioned, that’s really just going to collect those metrics, that person, there has to be a brain in the seat still, right? And that person needs to know what to do next. Now, again, say accidental DBA, but instead of just being one responsible for, pick up the phone to call somebody to fix it, let’s say you’re the one responsible for actually fixing it and you’re going to need some help. Well, that’s where a tool like DPA comes in. Now I speak to DPA because I’m a former customer. And I mentioned Sybase, right? So one of the things that I found incredibly valuable when it came to a tool like DPA was the fact that it did more than one platform. And it represented that information in a common way. So no matter if I was looking at an instance of Sybase or Oracle or DB2 or SQL Server, it would present the information, present everything in the same manner and format, but also gave me help, right? If I came across a wait event that I didn’t recognize, there was a definition for me, there was an idea of what was happening. And at some point in your career as a DBA, you start to understand that there’s only so many bottlenecks, memory, CPU, disk, network, locking, and blocking, and that’s for every relational database system out there. That’s how it works. So DPA would give me the insight and let me understand, like, where is it I need to go next? Now where I want to go next is I’m just going to drill into the SQL 2017 box. And I get information about what I’m looking at in this particular chart. I see here, these bars. I do joke, I say, even the manager can understand the bar chart. And I have yet to meet a manager that disagrees with that statement. But if I hover over one of these bars or verticals inside of this bar, right? I get information about that particular query. And you can see that the total wait time for the day is 49 hours. How can you have more than 24 hours in a day? Because it’s all executions. It’s a summary. It’s an aggregate. Everything you see in DPA is going to be an aggregate. So in this case I have 200,000 executions, but each one one only takes half less than half a second. So maybe that’s not an issue, but it’s still consuming resources. Now, most importantly is when you see that the number of hours of wait by day here, you can see that March 9th or 5th or 12th actually had higher amounts than say May 2nd, but check out what’s down here. This is anomaly detection. So we have actual math going on behind the scenes here. This is fairly new, past couple of years. We’ve put in machine learning, and I don’t use that term lightly like others might do where they say, well, it’s artificial intelligence, which is really just, I mean, that’s just an if/then/else statement is technically artificial intelligence. But this isn’t just performance against a baseline either. This is us looking at the time series of wait statistics that have been collected previously. And it’s filtering for seasonalities. And it’s saying, I predict on May 2nd we’ll have this amount of wait, total wait across all executions. And on May 2nd, we had something much different. And in this case we highlight it. So if you’re that person in the seat responsible for fixing something, this is your signal through the noise, right? This is you saying oh, I know that the there’s a bigger bar over here but something on May 2nd was different. This is the anomaly. This is where I need to go and focus my effort right now. And if you didn’t have any anomalies, where would you start? Well as a customer, this is where I would go. I was in the advisors tab a lot, I would pick out a particular statement and I’d say I need more information on why this was deemed critical, versus this one was just a warning. I can get that information. I can end up at what we call the query detail screen, where now I’ll get the, what we call intelligent analysis. Again, information, if there was any advisors, and that’s how I got here through the advisors. Here’s the table tuning advisors. We’re going to give you details on not just, hey maybe you want to add an index. We’re going to tell you, hey, if you change this index, it’s going to affect 74 queries that are hitting this table. That’s the level of detail that a tool, a higher level tool like SAM, isn’t going to give you, but a deeper dive of a diagnostic tool like DPA will. I also get information about locking and blocking for this particular query. If we go back real quick to that other screen, you’ll notice that there was locking and blocking down here as a tab for the instance itself. Kevin, how often do you find locking and blocking say the root cause of issues?
>>It’s hard to put a percentage on it. I would describe it more in terms of when you smell smoke, there’s a fire. So I would say that probably 40% of applications, 30 to 40% I find have locking and blocking problems. But when they do, they usually have massive locking and blocking problems because the development team didn’t really understand the whole idea of set-based processing as opposed to row-based processing. And so the whole application just goes haywire.
>>And this is why we’ve put this blocking tab front and center. Well, I say front and center, it’s slightly below the fold here, but it’s part of these tabs down below. The big bars are up top, I see this down here, I see there’s an anomaly, well, maybe somebody kicked something off on May 9th and this is really why that anomaly up top is there. So who’s running this? Well we can get all that information as well. We can drill through and get a wonderful amount of details inside of DPA as to who was running what and when, and that way you can go and have that conversation and say, hey is this something that you were expecting to happen? Like, what were you doing? Rebuilding an index? What is it that went wrong for you? How can I help you? Something else I want to show that we’ve just added in, is this Find SQL. If you’re not running the latest version of DPA, you might benefit from upgrading for lots of reasons. And one of which being that you can come in here and you could say I’m looking for, I don’t know, is there any inserts happening there? And there’s some inserts happening. But you might want to know the queries that were hitting a particular table. So we’ve given the ability for you to search fairly quickly. This is a common request from our customers was how can I search through all of these queries that you’ve collected in order to find a particular set? And well there’s always a way to do things, but we’ve decided now that should really be a a feature inside of DPA. So that’s why it’s there now. Lots of ways for you. I could spend hours talking about DPA, which I won’t, the point here I want to get you to understand is that if you need this extra level of diagnostic information from your database servers, cross-platform, if you want that high level, if you want that signal through the noise, you’re going to need a tool like DPA in order to get the job done.
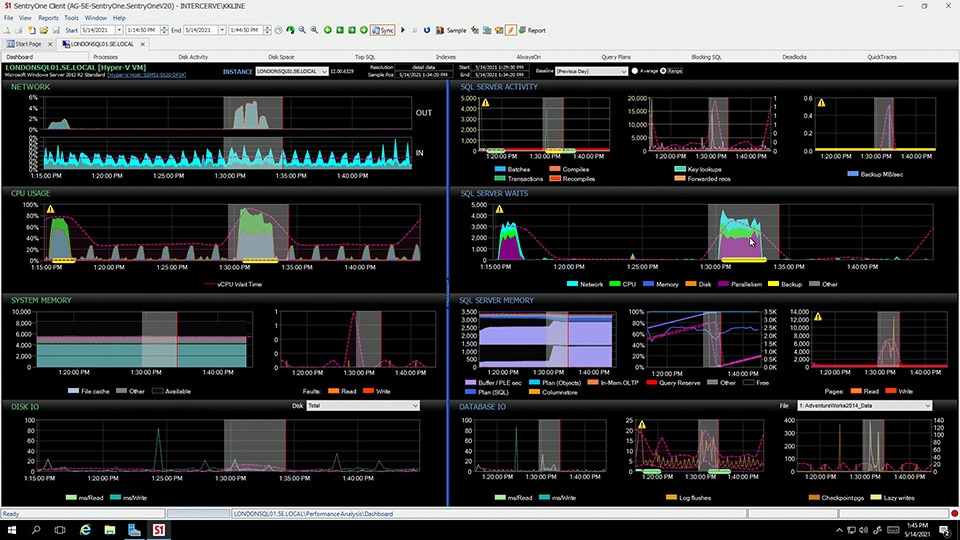
>>So, one of the things that you pointed out here, Tom is that we have a lot of information, not only about SQL Server, but as you pointed out when you started the demo, we also have Sybase, we have Oracle, we have MySQL and other data platforms. But what if you want to go much, much deeper than what all of these relational database platforms have in common? Well, that’s where SQL Sentry comes in. So what we’re looking at here is the default interface for SQL Sentry. And I’m going to explain a few things because the environment is very rich and sophisticated. The GUI offers a lot of information all at once. And I encourage you as you get to use the tool to customize it to how you work best. Because in fact, we display the same information, sometimes more than one way, because different people think different ways. And they process their data in different ways. So we want this to be as useful and usable by you as we can possibly make it. Just a few highlights on the starting page, over here on the right-hand side, you can see that we have a broad set of global conditions. These are general conditions for things like maybe the server is down. You can see, we have things like blocking SQL. We have event chain failures, which is a method of linking together SQL agent jobs. We have SQL agent job failures, and also notice that we have a variety of actions that you can do as well. The most common one is that you would like to get an email about it, but there’s other things too. We could execute a PowerShell script. We could execute a T-SQL script or fire a job. In fact, when you look at the combination of ways that we alert you and responses that you can have, either automated or to notify you, we’ve got the richest alerting and response system out there. We also have things like multiple targets who might get the notification. We have different schedules you can set up as well as condition settings, so you could say on weekends, we want this to go to a different schedule or perhaps a different set of DBAs. because the main DBAs are enjoying their weekend at home. There’s several different categories of alerts and conditions, which I’m not going to go into because just give you a broad scope of what’s going on. One of the really neatest ones is called advisory conditions. And these can be on anything in the stack. By that I mean, it could be the hardware, it could be the OS, it could be the hypervisor provider, it could be the hypervisor’s guests, the different VMs on it. And it could be not just SQL Server, but it could be integration services, reporting services, analysis services, anything that is inside a SQL Server. So SentryOne has always been passionate about SQL Server. And so we give you not just the broadest coverage for your SQL Server management, but also the deepest coverage in terms of the granularity of the different instrumentation you can look at, the metrics you can sample and pull, and the responses that you can generate from them. So, one thing on these advisory conditions that’s very interesting is that they have different kinds of rules associated with what they are going to teach you, and what they’re going to look for. So if you were to look at say data file growth, for example, if you were to look at the deeper details on this advisory condition, there’s always going to be a link that tells you why, a URL link that tells you why this is so important. So it might be a blog post to Microsoft documentation, or one of the eminent authorities on SQL Server, like Paul Randall at SQL Skills or others of the really really well-known independent experts on SQL Server. So we provide you this very, very deep, very customizable alerting and notification system. But the main thing that I love about the starting page is that we give you that enterprise scalability that Tom mentioned earlier. So this health score here is for all of my servers, and then below we see the different servers themselves. And in fact, if I open up my group over here on the left-hand side, I could see more information about the different SQL Servers I have. And of course, color coding is significant. So red means that there’s problems, yellow and orange means that they’re not severe or not as severe, but there are things you might want to look at. And so we can see all the different SQL Servers, Windows servers, VMs, and so forth. And from here, we could click on the server. We could click on the condition that it found, and actually jump to that specific period of time, okay? Believe it or not, a 60 out of 100 is not a terrible score. We’ve seen enterprises that are doing much much worse than that. And then if we clicked on any of these color-coding up here at the top, it would also filter of this for us. So if we said, you know what? I only want to see critical conditions that have occurred in the last 24 hours, I click critical, sure enough, it filters them all out for me. If I click it again, it restores that. So we have it by critical high, medium by severity here, and then we also have it by category. So maybe I know that I’ve been having problems with hard disks, and we’ve got an old SAN that we plan to replace soon. I could just click on the disk alarms and see all the issues that I might have going off related to disks. Another thing that’s neat about this interface is we actually have jump points. This is something that we build into the system throughout where we can jump to other parts of the GUI because there’s so many good things to look at and do more research on. One way that I always like to look at my SQL Server environment is just as a good old table. And so we can click this View Performance Stats. And what this does is this shows us a top-level performance metrics that you collect on the different servers, all in one tabular format. And so my favorite way to display this format is to click this Expand Warnings button. And so everywhere we see that red color-coding or orange color-coding, it will expand out all of those different servers. And then we can look for the specific problem that might be occurring on a given server. And when we see that particular one in red or orange, then we can click on that. So here we see PLE, a memory management counter, is in red. And if we click on that one, we can see what our PLE has been over time, right? So this is where it began to experience its really big differences that caused that alarm to go off. And again, we’re just looking at the last sample. So throughout the dashboards, you can change the time range you would like to look at. So we could just flip back to the last couple of hours. If someone was calling right now and saying, hey, what’s going on with my SQL Server? So we can see actually that over the last couple hours we have some real churn happening in our memory buffers. And that might be something worth investigating, because maybe we have a job that kicks off that isn’t necessarily needed to run every hour or so but it is, and it causes the entire data cache to flush. So that’s another way to look at things. We could look at them by alarms that go off. We could look at, so that’s this button right here, the action log will show us what’s going on. But commonly what I do is I come and look at this screen here, and I say, okay there’s a server that I want to take a look at. I’m looking at severity by, the servers and alarms by severity. So let’s take a look at this London SQL 01 for this long-running query that’s giving us some issues. And so now we can see all the times that’s happened. And we can also, as I mentioned before, we can see that link that will take us to a respected authority on the topic that tells us why we’re keeping an eye out for this particular condition. Or again, click right on the server itself. And then we’ll dive in to see what’s happening with that SQL Server. This takes us to the well-known interface for SQL Sentry. Let me get us a little bit more real estate here. Notice this blue bar right in the middle. This is an important division in the information that we’re seeing on the screen right now. Everything to the left of the blue bar is Windows-related performance counters. Everything to the right is SQL Server performance information, may not be a perfmon counter, it’s information from many different sources like DMV. So here, for example, SQL Server waits. This is largely the same thing, derived from the same sources as what we see in DPA. And so we can see there’s some really big spikes here, in the wait statistics as they’re happening over time. We also have different graphs on the right-hand side of the blue bar for problem situations in SQL Server. For example, key lookups, if I click on that, you can see them more clearly. Key lookups are a big issue that can really slow down your SQL Server. In the same way recompiles are also a big issue. Notice we also have a couple of warnings going off, so we have a little exclamation point that’s telling us, uh oh, your backups are taking a lot longer than usual. So that’s one thing that we see. And then we also have little dots that will appear at the bottom. These are advisory conditions as they are happening. And normally if you had just one experience of an alarm happening, you just see one dot. So we see it looking like a big fat line, that’s because it’s happening over and over again. So check this out. The most common thing we want to do, assuming we’re in the time range that we want. If you want to look at what was going on for the last month, we could certainly select that. One of the things that we like to do is we like to say well, how does this compare to what’s normal for the server? As Tom was mentioning, anomaly detection. One of the ways we provide something similar is we have built-in baselines that tell us what things look like under normal circumstances. And so this particular view is just the average. So yeah, actually this is normal to see a big spike like this. May not happen every single time at this time of the day, but it is normal. We could also switch over to the range, meaning I want to see the min and the max values that are normal during this period of time. So you can see the little field that shows what’s normal. But my favorite part here is that I can highlight a problematic situation, and it gives us instantaneous correlation across all of the different graphs that we see on this page. So sure enough, we see that there is a really big key lookups spike happening up here at the top. Along with that, our wait stats have gone way up. So we see that there’s some parallelism happening. We see that there is some CPU and network happening, but it also correlates over here on the left-hand side. So we know that the Windows server CPU has gone way up as well. It’s not uncommon for you to look at the left-hand side, and maybe you’ve got some experience as a SysAdmin, maybe you’re an accidental DBA, primarily as an admin. Well, sure enough, we see that yeah, the Windows server itself also got a lot busier. We know that this spike in SQL Server is correlated with the Windows server, but sometimes you’ll see situations where the CPU spike goes way up, but it doesn’t correlate to what’s happening in SQL Server. What’s going on there? In one humorous case, or maybe not humorous for the customer, but it was humorous for us. They actually discovered that their SysAdmins were loading Bitcoin miners onto their servers evening. And so they’d see the CPU peg at 100%. SQL Server wasn’t that busy though. And so they immediately started to do some research to find out what this strange behavior was between 1:00 AM and 6:00 AM. And sure enough, somebody was trying to make a buck on their employer’s server. Now what’s the normal thing you would do when you see a big spike like this? Of course we’ve already got it set up to alert us that there’s a problem, but we want to dig deeper, right? So we can right click here, and we could A, zoom in to this timeframe, and just get a really tight view of that. But then on another click we could say, what I really need to do is I need to look at the top SQL statements that were happening during that time, because there has got to be a problem here. Something is wrong with our SQL statements. And so in a situation like that, we might want to jump over to the top SQL page, and you can see all the tabs here that we have, across the different aspects of the SQL Server. So we could also look at blocking and deadlocking. So there is an active block happening here. Again, we could look at maybe what’s happening with disk space or disk activity. And I’ll go to the here and now on the disk activity tab and set it to auto refresh. So we can see that these are write operations going into the databases. Across the top we would see read operations pulling data out of the databases. Anywhere that we would see red on here, perhaps at the disk, or even further back on the controller back plane here, it turned red, we would know that there was an issue on that particular SQL Server. And so when we click on those different objects, it will show us at the bottom all the activity and all of the disk-related information about what’s going on now. But we wanted to see top SQL. So let’s take a look at that. What was the SQL that was running at that time that was giving us an issue? Well, first thing that we see here on the left-hand side is we see the SQL statement running at that time. We see some orange highlighting, and if you hover over any of the highlighting, that let’s you know with a tool tip what’s going on. So in this case, we see that the estimated rows, very very different than the actual rows, of what the query optimizer expected. And so that tells us that the statistics on the indexes in use here were a problem. And there’s a lot more data as well about the performance of the SQL statement. For example, it does a hash match and a sort operation. So we know in those cases that it’s actually spilling some work-over into tempdb. Down here at the bottom, one of the things we can see is that there’s lots of dots. What are those? Those are actually the execution plans stored in the plan cache. Because they are all the same color, we know that SQL Server is actually reusing a plan a lot, which is great. But on the other hand, we see some of these are very much an outlier. And so in a case like that, we might want to jump to, let’s say, locking and blocking or something along those lines, to see if the reason it took so long to run was because of a block. You can check those different aspects of it, okay? And then of course we have direct integration with our very popular free tool called Plan Explorer. And so we can actually look at each of these and see what is going on with the execution plan itself with a very, very nice color-coding so that we can see, oh you know what? Most of the costs for this particular query is coming in right here at this nested loop join. And that’s where it’s spilling to tempdb. So this is very similar at the bottom, by the way, very similar to what we have in query store, except this goes back to, we support this functionality all the way back to SQL Server 2000, basically. So it’s a superset of what you get with query store. Now that’s a very brief example of the diagnostic process. One other thing I would like to show you, I’ll go back to the start page here, is that we can also look at everything that’s happening on our SQL Servers using a interface very much like what we have in Outlook calendar. So let me go ahead and open up the navigator once again. And we can do this by server. So we could go to this London SQL 01 and we could on a right click, open up the event calendar. And this will show us all of the activities that were scheduled either by Windows Scheduler or SQL agent on this particular SQL Server. Notice how busy it is, right? So of course, we’re going to want to filter that, and we have several different ways to do that. You can do it by the entire server environment, all of your servers, we could do different kinds of advisory condition views, perhaps. So let’s say we’ll open it by advisory conditions. Now, just to give you a quick idea of also how this works, is we’re looking at a full day, let’s go down to a much smaller timeframe. Let’s go down to the last hour. And you saw lots of different colors. So again, there’s lots of color coding happening here. And so just in the last hour, we’ve got one situation where there’s a long-running open transaction. We also have another situation with a long-running transaction, but notice that there’s blue here. Well, in this particular one-minute time, or two-minute timeframe, that little tiny blue means that’s how long it took for the SQL statement to run. Whereas over here, two minutes runtime it was about half of that runtime. And then if we were to look at other aspects of it, you might see some of these were in red, some of these. So some of these were in red, some of these were in yellow. Each of those different things means, it gives you a different set of context as to what happened with each of these different jobs. If it’s red, that means it failed. If it’s orange, maybe it was running in conflict with another job that was taking resources for it, and so forth. So it’s a really neat way to see multiple different things that are happening on your SQL Server. A lot of times your tasks and jobs get excluded from your troubleshooting. And so this is a neat way to integrate more of it. One other thing I do like to point out too, is this runtime stats. You can get runtime stats on most any actions that your system is doing, but just like what Tom was saying around anomaly detection, this is a bit more direct in terms of this one thing. Here’s what is normal and what is abnormal. So we can see what our minimum normally is. We see a line for the average, and then we can see what the max times are for the run. And we can see if, we can click on those, jump to that point in time and see what the differences were literally, between the minimum runtime and these maximum runtimes. Maybe there’s something we need to tune there. So again, we get all of these different features, not just for SQL Server, but we get them also for analysis services, and SQL Server in the cloud, SQL Server on-premises and so forth. So in looking at the dashboard, you see all of the OS-level details here. SQL Server on the right, but also notice here there’s a hyperlink. That’s because this particular instance of SQL Server is running on a virtual machine. And by clicking on that hyperlink, it takes us to the VM host. One of the things that’s really neat about this is we see the consumption of resources by the guest on the left side. And on the right-hand side we see the consumption of resources for the entire host. If it’s VMware server or a Hyper-V server. So we could see if we have one of those classic noisy neighbor problems, maybe the host is running an Exchange server as well, and that’s what’s sucking up all of the resources. So again, we took a little extra time here to show you SQL Sentry. But the reason for that is it’s a specialized tool designed for SQL Server of the highest importance. And it will take you all the way from the low level server and OS up through the virtualization layer, into SQL Server and give you multiple ways to see all the things happening in SQL Server.
>>Kevin, this is fabulous. I love the view and the tie in with virtualization. One of the first things that we built when I joined Confio way back is the Ignite VM. We got the VM metrics, so you’ve got that correlated view of query performance and guest level on the host. And it’s still there in DPA, I didn’t show it today. Look, there’s a lot to these tools. There there’s a lot of features and functionality. And the reason is because databases have a lot of importance to a business, and our tools have these features and functions because we want our users to be able to add that value back to their business. And that’s why, we could spend hours going through all of this stuff, but we don’t have that much time today. So we’re going to come out of this and we’re going to wrap things up. So Kevin, look, we covered how these two tools work separately and possibly together. So I want to make sure we help the viewer, our customers, understand when would it make sense to have one tool versus the other, any advice that you could offer?
>>Well, one of the great things about us coming together as two companies is that you don’t really even have to choose. We do have a new package called Database Insights for SQL Server in which you’re licensed on both. And so if you have servers where you need to pay attention to multiple platforms and SQL Server, and then you also need SQL Server really that deep dive monitoring, you can have that. And so keep that little thought in mind with Database Insights, but also there are those general differences between the two products. If you’re SQL Server only, of course you could use both products, but if you have Oracle, if you have Sybase, any of those other data platforms, you’re going to want DPA because it gives you that single pane of glass across all of your different kinds of database servers, very powerful feature.
>>And our database portfolio really doesn’t stop with just these two tools. So if you are doing cloud-native distributed applications you’re going to want to look at Database Performance Monitor which we didn’t have time to talk about today. But we also have other tools from SentryOne. I forget the names, you can help me out here.
>>Right Tom, there’s two main ones I want to mention, which is Task Factory, which takes and offers you a variety of different pre-built SSIS packages. Some are very common challenges that you just want to work really fast. Others are some common SSIS packages that you’d have to build yourself that’s hard to do, like how to extract Google Analytics data and Salesforce data and things like that. Great for any shop that uses a lot of SSIS. And then on top of that, one of my favorite products actually, Database Mapper. And Database Mapper will build database documentation for you. It’ll build your data dictionary and a very powerful feature called data lineage, which will actually show you where the data came from at inception. Maybe it started on a point of sale system that sends CSV files to you. And then it goes through a staging server and production into a data warehouse. So if you needed to change something on the data warehouse, you could pull that data lineage report, and see all the places you’d have to change things.
>>I mean, we could spend eternity it seems like, talking about all of the database products that we have here at SolarWinds right now. I mean, again, we focused on two today, three really, but there’s a lot more that we have to offer. I don’t know of a company that has a more comprehensive suite of database tools than SolarWinds right now. So again, we could do this all day, but we’re going to wrap it up. I want to thank again, everybody for taking the time to come join us here today. We do know you have your choice, and if you chose to spend it with us, Kevin and I are very grateful and that’s really it. Kevin, thank you for your time today. Appreciate it.
>>Yes, sir. Thank you.
>>And it was great having you as always, and for SolarWinds Lab, for Kevin Kline, I’m Thomas LaRock. Thank you for watching. [electronic music]





