Modern IT environments are so complex, dynamic, and expansive that humans alone cannot effectively manage and maintain them. As a developer and operator, I have had to deal with failed servers and containers, running out of storage space, slow or unreliable network links, bugs in code, and unpredictable workloads in some applications. In the worst-case scenario, I experienced a severe service outage that generated an overwhelming number of alerts from multiple levels of the application stack, a flood of log messages, dashboards with key indicators clearly indicating something was wrong, and I had too little time to try to make sense of any of it.
Of course, this doesn’t fit in the category of “Breaking News”—the challenges of managing IT infrastructure are not new. However, automation isn’t new, either. IT professionals have long used tools to automate repetitive and predictive tasks like running backups or distributing patches to operating systems. They’ve also used performance monitoring tools and alerting solutions to watch for known problems that can crop up and disrupt services, like availability issues and downtime caused by running out of persistent storage on a database server that can often impact end-user experience.
What is new is the scale and diversity of infrastructure and services running on that infrastructure, and the need for artificial intelligence-based tools and techniques for dealing with these new challenges. To operate IT infrastructure at the scale enterprises are working with, we must apply more advanced automation to ensure the availability, performance, and scalability of our systems. It’s commonly known as “AIOps.”
Defining AIOps
AIOps is a collection of technologies, tools, and processes used to manage IT operations at scale. Artificial intelligence (AI) is required because it’s simply not feasible for humans to manage modern IT environments without intelligent automation.
Even if an organization could afford to keep adding IT operations staff, it’s not likely that even a large group of humans could effectively manage multi-cloud infrastructures and other use cases. This is especially true of cybersecurity risks. And seeing how AI is increasingly used in cyberattacks, it’s best to have AI in place to respond in kind.
Common AIOps Use Cases
The popular press has shared news of advances in AI and how it can help doctors diagnose disease, improve driving safety, and predict demands for products. And although it receives less fanfare, the application of AI to IT ops is a crucial step toward managing increasingly complex IT infrastructure. The latest step in the evolution of IT operations is applying AI to manage workflows, infrastructure, and services without human intervention.
The evolution of IT infrastructure with the advent of cloud computing and big data has led to larger fleets of servers, more storage systems, and more complicated networks. This has led to more than just an increase in the quantity of devices and services we need to manage—there’s been a qualitative change in the level of complexity of the systems we need to manage.
This is perhaps most starkly seen in the realm of infrastructure, which is no longer confined to a small number of on-premises data centers—it now extends across multiple cloud platforms (see Figure 1). As organizations adopt digital transformation initiatives, more applications and services are brought online. A downside of these expansions is that they increase the attack surface, which can be exploited by cybercriminals.
 Figure 1: The increasing complexity of IT infrastructure has created the need for AIOps
Figure 1: The increasing complexity of IT infrastructure has created the need for AIOps
What are the Five Key Stages of AIOps?
AIOps includes multiple stages as shown in
Figure 2:
1. Data ingestion
2. Data integration
3. Event correlation
4. Problem detection
5. Problem remediation
Each stage serves a distinct purpose that moves from collecting raw data through transformation and analysis to performing actions to remediate problems. From a quantitative perspective, the goal of AIOps is to decrease the time to detect, investigate, and resolve issues in your IT environment.
 Figure 2: The stages of the AIOps pipeline
Figure 2: The stages of the AIOps pipeline
1. Data Ingestion
The first stage of AIOps is to collect data sets from various source systems, including servers, networks, apps, and other systems. To minimize the time to detect and resolve issues, it’s important to capture data in real-time or near-real time. This requirement means that support for streaming ingestion is crucial.
It’s also important to keep historical data, which can be used for refining AIOps machine learning models and support other tasks, such as capacity planning and security incident investigation.
Another important aspect of data ingestion is normalizing or standardizing the aggregate data. Different source systems may use slightly different data structures for the same kind of data, so it’s important to map data to a common structure to support the advanced analytics that can come at later stages.
2. Data Integration
The second stage of AIOps is data integration. This is when data from different sources is linked in ways that enable more informed root cause analysis of data across source systems. For example, an application may generate a series of metrics about performance and load on the applications, along with log messages describing significant events in application processing. By aligning metrics and logs by time into a common dashboard, it becomes easier to find patterns of correlation between events and dependencies to better inform application performance management (APM) insights.
3. Event Correlation
Event correlation is the process of identifying related events that are useful for understanding the state of a system. The goal of correlation is to connect the dots of interesting events from a massive stream of possibly interesting events.
For example, assume a network device reports metrics indicating an increase in traffic, followed by a load balancer reporting a similar increase. Next, servers in the load-balanced cluster report unusually high CPU and memory utilization. Normally, the load balancer would add additional virtual machines (VMs) to the cluster when CPU utilization exceeds a defined threshold. But if that doesn’t happen, immediate steps are needed to correct the resource shortage.
4. Problem Detection
The load balancer failing to increase the number of VMs in the cluster is an example of a problem that can be detected via event correlation, along with applied pattern matching and other AI techniques to the correlated data.
While humans can and do define some patterns, machine learning algorithms are adept at anomaly detection and performing other predictive analytics to identify patterns of interest in large volumes of IT data. This ability allows AIOps systems to learn and expand the scope of problems they can detect.
5. Problem Remediation
The final stage of the AIOps pipeline is to correct the problem detected. In the failed load balancer example, additional resources could be added to the cluster. If the event was related to an ongoing security breach, the AIOps system could block network ports, terminate sessions, and perform other steps, such as patching known vulnerabilities on the systems under attack.
Is AIOps the Same as DevOps?
It should be noted that AIOps complements DevOps, another methodology essential to the management of modern IT operations.
Even though both terms use “Ops,” it’s important to note the differences.
DevOps is a set of best practices that streamline software development, software deployment, monitoring, and continual updating of that software. It allows software developers, IT organizations, and systems operators to work more effectively and can help reduce departmental silos.
DevOps focuses on the software development lifecycle, while AIOps focuses on ensuring that software in production is operating efficiently, securely, and reliably.
Although AIOps and DevOps are different, they share some common characteristics (see
Figure 3). Both use automation to improve the capabilities of software developers and IT operations teams. Both depend on defined, well-orchestrated pipelines for implementing an established series of steps.
Both also focus on continual improvement and optimization. In DevOps, this can be accomplished by rapidly updating and releasing new software versions. In AIOps, this is accomplished by continually collecting and integrating data and using the product of those operations to improve the machine learning models that underly the detection and remediation stages of AIOps.
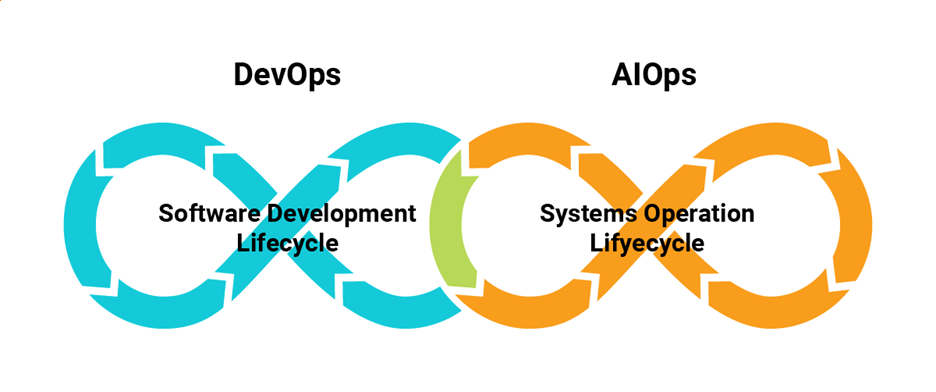 Figure 3: AIOps complements DevOps
Figure 3: AIOps complements DevOps
Benefits of Using an AIOps Platform
If you’re working with complex IT infrastructure, then you’re probably familiar with the challenges of delivering scalable services that run reliably and efficiently in constantly changing IT environments. The days of automating operations with hand-crafted scripts are gone.
IT pros need tools designed to ingest large volumes of data, integrate multiple sources of data, correlate events across data sources, detect problems, and resolve those problems with new technologies to support more efficient IT systems. This is the function of AIOps. With all the opportunities AIOps can provide to help streamline workloads and processes, bringing in a trusted partner with AIOps solutions and AIOps tools can help ensure you are fully benefiting from AIOps to support and accelerate your digital transformation.
How AIOps + Observability Can Help
System complexity, while a common problem, is a problem of our own making that demands a different type of solution to solve. Instead of relying on manual tasks and disparate tools that only provide surface-level visibility, by solving for observability across our infrastructure, we have taken the first step to gain deeper insight into the “why” behind system failures and can more effectively leverage AIOps to stay ahead of performance problems.
You can learn more about how
SolarWinds® Hybrid Cloud Observability is built to give you single-pane-of-glass
observability with actionable AIOps to more easily automate visualizations, remediation, and troubleshooting across IT environments located on-prem, in the cloud, and hybrid deployments. With advanced analytics, observability can help you more easily identify and diagnose service issues and root causes ahead of system problems occurring, which can allow organizations to shift from reactive to proactive workflows.






